
Data science with Python: Turn your conditional loops to Numpy vectors
Vectorization trick is fairly well-known to data scientists and is used routinely in coding, to speed up the overall data transformation, where simple mathematical transformations are performed over an iterable object e.g. a list. What is less appreciated is that it even pays to vectorize non-trivial code blocks such as conditional loops.

”http://www.freepik.com" Designed by Harryarts / Freepik
Python is fast emerging as the de-facto programming language of choice for data scientists. But unlike R or Julia, it is a general purpose language and does not have a functional syntax to start analyzing and transforming numerical data right out of the box. So, it needs specialized library.
Numpy , short for Numerical Python, is the fundamental package required for high performance scientific computing and data analysis in Python ecosystem. It is the foundation on which nearly all of the higher-level tools such as Pandas and scikit-learn are built. TensorFlow uses NumPy arrays as the fundamental building block on top of which they built their Tensor objects and graphflow for deep learning tasks (which makes heavy use of linear algebra operations on a long list/vector/matrix of numbers).
Many Numpy operations are implemented in C, avoiding the general cost of loops in Python, pointer indirection and per-element dynamic type checking. The speed boost depends on which operations you’re performing. For data science and modern machine learning tasks, this is an invaluable advantage.
My recent story about demonstrating the advantage of Numpy-based vectorization of simple data transformation task caught some fancy and was well received by readers. There was some interesting discussion on the utility of vectorization over code simplicity and such.
Now, mathematical transformation based on some predefined condition are fairly common in data science tasks. And it turns out one can easily vectorize simple blocks of conditional loops by first turning them into functions and then using numpy.vectorize method. In my previous article I showed an order of magnitude speed boost for numpy vectorization of simple mathematical transformation. For the present case, the speedup is less dramatic, as the internal conditional looping is still somewhat inefficient. However, there is at least 20–50% improvement in the execution time over other plain vanilla Python codes.
Here is the simple code to demonstrate it:
import numpy as np
from math import sin as sn
import matplotlib.pyplot as plt
import time
# Number of test points
N_point = 1000
# Define a custom function with some if-else loops
def myfunc(x,y):
if (x>0.5*y and y<0.3): return (sn(x-y))
elif (x<0.5*y): return 0
elif (x>0.2*y): return (2*sn(x+2*y))
else: return (sn(y+x))
# List of stored elements, generated from a Normal distribution
lst_x = np.random.randn(N_point)
lst_y = np.random.randn(N_point)
lst_result = []
# Optional plots of the data
plt.hist(lst_x,bins=20)
plt.show()
plt.hist(lst_y,bins=20)
plt.show()
# First, plain vanilla for-loop
t1=time.time()
First, plain vanilla for-loop
t1=time.time()
for i in range(len(lst_x)):
x = lst_x[i]
y= lst_y[i]
if (x>0.5*y and y<0.3):
lst_result.append(sn(x-y))
elif (x<0.5*y):
lst_result.append(0)
elif (x>0.2*y):
lst_result.append(2*sn(x+2*y))
else:
lst_result.append(sn(y+x))
t2=time.time()
print("\nTime taken by the plain vanilla for-loop\n----------------------------------------------\n{} us".format(1000000*(t2-t1)))
# List comprehension
print("\nTime taken by list comprehension and zip\n"+'-'*40)
%timeit lst_result = [myfunc(x,y) for x,y in zip(lst_x,lst_y)]
# Map() function
print("\nTime taken by map function\n"+'-'*40)
%timeit list(map(myfunc,lst_x,lst_y))
# Numpy.vectorize method
print("\nTime taken by numpy.vectorize method\n"+'-'*40)
vectfunc = np.vectorize(myfunc,otypes=[np.float],cache=False)
%timeit list(vectfunc(lst_x,lst_y))
# Results
Time taken by the plain vanilla for-loop
----------------------------------------------
2000.0934600830078 us
Time taken by list comprehension and zip
----------------------------------------
1000 loops, best of 3: 810 µs per loop
Time taken by map function
----------------------------------------
1000 loops, best of 3: 726 µs per loop
Time taken by numpy.vectorize method
----------------------------------------
1000 loops, best of 3: 516 µs per loop
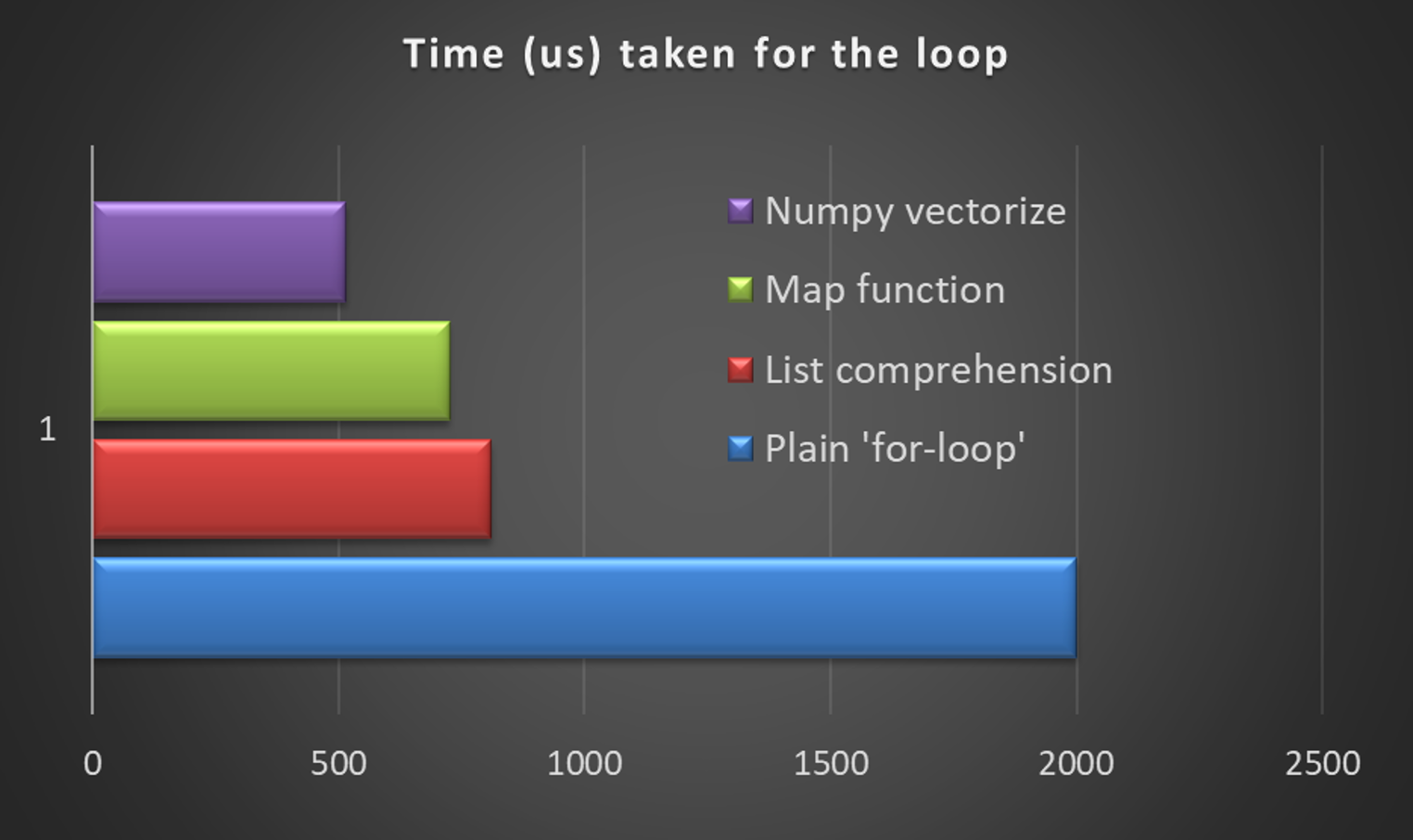
Notice that I have used %timeit Jupyter magic command everywhere I could write the evaluated expression in one line. That way I am effectively running at least 1000 loops of the same expression and averaging the execution time to avoid any random effect. Consequently, if you run this whole script in a Jupyter notebook, you may slightly different result for the first case i.e. plain vanilla for-loop execution, but the next three should give very consistent trend (based on your computer hardware).
We see the evidence that, for this data transformation task based on a series of conditional checks, the vectorization approach using numpy routinely gives some 20–50% speedup compared to general Python methods.
It may not seem a dramatic improvement, but every bit of time saving adds up in a data science pipeline and pays back in the long run! If a data science job requires this transformation to happen a million times, that may result in a difference between 2 days and 8 hours.
In short, wherever you have a long list of data and need to perform some mathematical transformation over them, strongly consider turning those python data structures (list or tuples or dictionaries) into numpy.ndarray objects and using inherent vectorization capabilities.
Numpy provides a C-API for even faster code execution but it takes away the simplicity of Python programming. This Scipy lecture note shows all the related options you have in this regard.
There is an entire open-source, online book on this topic by a French neuroscience researcher. Check it out here.
If you have any questions or ideas to share, please contact the author at tirthajyoti[AT]gmail.com. Also you can check author’s GitHub repositories for other fun code snippets in Python, R, or MATLAB and machine learning resources. If you are, like me, passionate about machine learning/data science/semiconductors, please feel free to add me on LinkedIn.