
Demystifying Asynchronous Programming Part 1: Node.js Event Loop
As a Node.js programmer, how can you not be familiar with the behavior of asynchronous programming? In this piece, I want to combine some of my experience and insights about the Node.js event loop and event pattern. It can’t just be superficial though, it’s gotta go a little deeper, but it still has to be easy enough for everyone to understand.
This post is my attempt to do what I just said. It took me several nights and nearly 20 hours to write (I know right…?!). I really wanted to write a shorter piece, but found that there's no way I could include everything in just a few short sentences. However, as much as I wrote, there's bound to be some things that slipped my mind. So please, don't hesitate to let me know if you find something wrong so we can make this post as accurate as possible!
In Short: Did you know that you can no longer use process.nextTick() to split your long-running tasks? If you already have a good understanding of the asynchronous nature of Node.js, you can skip ahead to the “Warning!” part of this post to learn more about the official reminder Node.js gave to developers.
The rest of the post may seem long, but that’s because I included some source code. Before moving on, please relax and give me 20 minutes of your time and some patience for me to clear up the fog.
First, a snippet of code: Take a Guess at the output order of console.log
To get your feet wet, let’s look at the code below. What’s the order of the output messages? Let's test your knowledge of Node.js asynchronous behavior.
console.log('<0> schedule with setTimeout in 1-sec');
setTimeout(function () {
console.log('[0] setTimeout in 1-sec boom!');
}, 1000);
console.log('<1> schedule with setTimeout in 0-sec');
setTimeout(function () {
console.log('[1] setTimeout in 0-sec boom!');
}, 0);
console.log('<2> schedule with setImmediate');
setImmediate(function () {
console.log('[2] setImmediate boom!');
});
console.log('<3> A immediately resolved promise');
aPromiseCall().then(function () {
console.log('[3] promise resolve boom!');
});
console.log('<4> schedule with process.nextTick');
process.nextTick(function () {
console.log('[4] process.nextTick boom!');
});
function aPromiseCall () {
return new Promise(function(resolve, reject) {
return resolve();
});
}
Output:
<0> schedule with setTimeout in 1-sec
<1> schedule with setTimeout in 0-sec
<2> schedule with setImmediate
<3> A immediately resolved promise
<4> schedule with process.nextTick
[4] process.nextTick boom!
[3] promise resolve boom!
[1] setTimeout in 0-sec boom!
[2] setImmediate boom!
[0] setTimeout in 1-sec boom!
(Note: On your PC, the outputs [1] and [2] may happen in a different order from mine)
Alright, let's see what happens if these things happen in an I/O callback. Below is the same code, stuffed into readFile(), a callback function from the asynchronous I/O API:
var fs = require('fs');
fs.readFile('./file.txt', 'utf8', function (err, data) {
if (!err) {
console.log('[I/O Callback get called] ' + data + '\n');
console.log('<0> schedule with setTimeout in 1-sec');
setTimeout(function () {
console.log('[0] setTimeout in 1-sec boom!');
}, 1000);
console.log('<1> schedule with setTimeout in 0-sec');
setTimeout(function () {
console.log('[1] setTimeout in 0-sec boom!');
}, 0);
console.log('<2> schedule with setImmediate');
setImmediate(function () {
console.log('[2] setImmediate boom!');
});
console.log('<3> A immediately resolved promise');
aPromiseCall().then(function () {
console.log('[3] promise resolve boom!');
});
console.log('<4> schedule with process.nextTick');
process.nextTick(function () {
console.log('[4] process.nextTick boom!');
});
}
});
function aPromiseCall () { // ...
Output:
[I/O Callback get called] read file boom!
<0> schedule with setTimeout in 1-sec
<1> schedule with setTimeout in 0-sec
<2> schedule with setImmediate
<3> A immediately resolved promise
<4> schedule with process.nextTick
[4] process.nextTick boom!
[3] promise resolve boom!
[2] setImmediate boom!
[1] setTimeout in 0-sec boom!
[0] setTimeout 1-sec boom!
(Note: On your PC, the outputs [2] and [1] will definitely happen in the same order as mine)
Now, calm yourself and let us take a closer look at the asynchronous mechanisms of Node.js. I mean, really calm down, because I sincerely hope you can get a hang of it by just reading through this post once.
Warmup: JavaScript Event Loop and Asynchronous Mechanisms
A lot of books and posts on the Internet have briefly covered JavaScript event loop and its asynchronous behavior. With actual implementation experience, I'm sure every JS developer has a rough idea about this topic.
If you're not very comfortable with the topic, you can spend some time on watching two of Philip Roberts’ videos below. The first one is about 15 minutes long and is done very well. He succinctly describes how JS mechanisms, such as single thread, single call stack, and callback queues, work together — it's very easy to understand. The second one is a presentation he did at JSConfEU — it is pretty much about the same things as the first one, but has an extra demo webapp. You can skip it if you want. Of course, if you know your stuff, you can go ahead and skip both videos.
- Help, I’m stuck in an event-loop - Philip Roberts
- What the heck is the event loop anyway? | JSConf EU - Philip Roberts
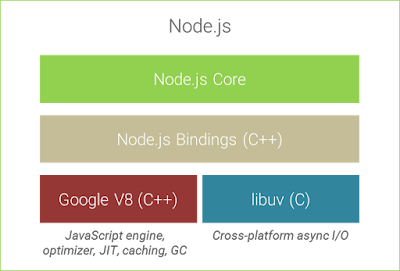
What happens in our browser is pretty easy to understand. It’s slightly more complicated if we're talking about server-side Node.js as opposed to the browser though. Node.js uses the Google V8 JavaScript engine, while using their own libuv to process I/O. libuv puts I/O controls from different OS in a package in order to provide a uniform asynchronous/non-blocking API and establish event loops. When we’re talking about Node.js event loops, it will be related to libuv.
Is Node.js Really Single Thread?
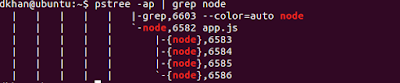
When people talk about Node.js, a lot of times they’ll say it runs in a single thread environment, but in practice, it runs multiple threads underneath. In his post How to track down CPU issues in Node.js, Daniel Khan starts off with a node application app.js and shows you all the processes that are running in it. I’ll let Mr. Khan tell you about it (I can’t tell it any better myself)
The famous statement ‘Node.js runs in a single thread’ is only partly true. Actually only your ‘userland’ code runs in one thread. Starting a simple node application and looking at the processes reveals that Node.js in fact spins up a number of threads. This is because Node.js maintains a thread pool to delegate synchronous tasks to, while Google V8 creates its own threads for tasks like garbage collection.
The libuv Event Loop and Loop Iteration
In the libuv core, there is a uv_run() function. The first parameter of the function is a pointer that points to the structure, uv_loop_t. Here, the uv_loop_t structure is the event loop. Every time the uv_run() is executed, it is considered an event loop iteration (uv_run() is a verb here).
The uv_run() function is clearly written and easy to reason about. We don't have to pore over the details; all we need to do is to know that when the function is executed, it runs in order functions, which includes: uv__update_time(), uv__run_timers(), uv__run_pendings(), ... , and uv__run_closing_handles(). Each function is called a phase of the event loop. The event loop will go through all these phases when it runs from start to finish.
Below is part of the libuv core.cc (core.cc source code), which you can just skim through.
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
// ...
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);
uv__run_timers(loop);
ran_pending = uv__run_pending(loop);
uv__run_idle(loop);
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
uv__io_poll(loop, timeout);
uv__run_check(loop);
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
// ...
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
// ...
return r;
}
Explanation of Event Loop from the Official Node.js Documentation
The guys at Node.js were kind enough to attach a document with the source code that very concisely explains how event loops work, so we can learn a thing or two about event loops without painstakingly going over the source code.
I redrew the following diagram from a figure in the document and added the phase functions to the tasks for a side-by-side comparison. This should be clear enough. I think every Node.js developer should take a good look at this document. If you're really too lazy to read, I've highlighted some of the most important points below. First, I want to clarify something about the I/O callbacks in the right side of the figure. Callbacks such as system errors (e.g. ECONNREFSED, a socket error) are queued here, and correspond to the uv__run_pending() phase. For a normal I/O request, the callbacks are executed in the poll phase.

Summary of Event Loop Characteristics
- Every phase has its own FIFO queue of callbacks related to the phase
- Upon entering a phase, the phase will synchronously run the callbacks in its queue’s order until all have been executed (or the upper limit reached) before moving on to the next phase.
- This why we say, don’t run intensive tasks in the callback, or the event loop will be blocked.
- When an event loop iteration is completed, it checks for any asynchronous I/O or timers that are waiting to be processed. If not, the event loop exits.
- For example, if you write an app.js with only the line
console.log('Hello'), it’ll exit as soon as that line has been executed. On the other hand, if you writehttp server.listen(3000, function(), { ... }), once it’s invoked, it’ll keep running because a socket has been opened in the lower layers and will keep waiting for an I/O event unless you close it.
- For example, if you write an app.js with only the line
Description of each Phase
- timer: runs the callbacks added to the queue by
setTimeout()andsetInterval() - I/O callbacks: every callback related to system errors is queued here
- idle, prepare: internal use
- poll: retrieves new I/O events from the system and runs corresponding I/O callbacks
- check: runs the callbacks added to the queue by
setImmediate() - close callbacks: listens to callbacks from I/O close event callbacks (e.g. socket.on(‘close’, ...))
How to Add a Task (or Callback) to the Event Loop
It's very important to know how to add a task to the event loop. You may think it's no big deal, but it has everything to do with how to write asynchronous code that behaves correctly.
- Using
setTimeout()andsetInterval()of a timer.- The callbacks are added to the timer phase queue
- Using the non-blockign IO API of libuv
- Such as sockets or filesystem API, or asynchronous API such as fs.readFile() in the node.
- Using
setImmediate()- The callbacks are added to the check phase queue
- Through
process.nextTick()- This is part of the node event loop, but not part of any phase in libuv. I’ll explain this later on.
- There’s one more thing that wasn’t mentioned in the document — using Promise (microtask)
- This is part of the node event loop, but not part of any phase in libuv. I’ll explain this later on.
How long exactly is a tick?
Earlier, we saw process.nextTick() as part of the API. Have you ever thought about just how long a tick is? This answer on Stackoverflow answers it quite concisely:
A tick takes as long as it takes for one event loop iteration, where every callback in the queues has been executed synchronously and in order. So the duration of a tick is not fixed. It could be long, it could be short, but we want it to be as short as possible.
So, again, all Node.js developers will tell you this: don't run long-running tasks in a callback! What happens is you’ll block the event loop. When you stretch out a tick, the event loop won’t be able to check for I/O events as often in a given amount of time, which means losing performance for your asynchronous code.
Order of Execution
Please read the section on Phases in Detail from Node.js document for more about order of execution. I’ll summarize it with a few key points.
Let's take a look at the figure below again. Even though the loop looks like it began at timers, even in libuv, but it’s not entirely so. Let’s put it this way, event loop is a closed loop — when it first kicks off, it really does start from the timers phase. But if you look at it long enough, with a closed loop you can pick any point and call it the start. The purpose of the program usually has to do with I/O. For example, if you open a socket, you can say that the event loop is built around the poll phase because you will always stop at the poll phase for a bit, do what you gotta do, then look around to see if there's anything else that needs to be done. You’ll see that a lot of discussions on the Internet, including this official documentation, center around the poll phase. Take note of this line from the official documentation:
Technically, the poll phase controls when timers are executed.
The official explanation is kind of all over the place, so let me summarize it according to my own understanding. If we start from the poll phase, the order would look like this:
- poll phase: process I/O events first while keeping an eye on timers that are about to expire. Move on to check phase when everything has been processed.
- check phase: process items added by
setImmediate(); if none, or if they’ve all been processed, then roll back to timers to see if anything's about to expire. - Then move on to poll phase: process I/O events first while keeping an eye on timers that are about to expire.
- General Principle
- If a timer is about to expire, but an I/O event occurs first, then the I/O event gets processed first before the expired timer is processed. As a result, the timer callbacks are not guaranteed to be processed on time.
- Taking an example from the official website: if a timer is set to expire in 100ms, but before then, an I/O event occurs, then the I/O event will be processed first, and the timer callback may be delayed to, say, 105ms before being executed.
- Overriding Principle
- Every callback queued via
process.nextTick()must be processed in order and synchronously at the end of each phase and before the beginning of the next. - So, you can never ever run a long-running task in a
process.nextTickcallback function. - Don’t execute functions that recursively call
process.nextTickbecause then the phase will always detect one more callback to run and the event loop is forever blocked in that phase.
(If any of you think I got it wrong after reading the official documentation yourself, please let me know!)
- Every callback queued via
setTimeout() and setImmediate()
setTimeout()belongs to the timers phase. It is designed to be executed when timed out.setImmediate()belongs to the check phase. It is designed to be executed after every poll phase.setImmediate()doesn't depend on a timer, but Node.js still included this API function in the timers core modules.- Of the two methods, if called during an I/O cycle, the callback of
setImmediate(cb)will run first (because the next phase is the check phase). If not called during an I/O cycle, the order of execution ofsetImmediate(cb)and a zero-secondsetTimeout(cb, 0)is non-deterministic. - Going back to the “guess the output” exercise at the beginning of this post, the question about the order of
[1]and[2]is answered here.
process.nextTick() and setImmediate()
process.nextTickdoes not belong to any phase (explained later)- The callbacks queued by
process.nextTick()will all be invoked before the current phase finishes. Which means, if you recursively callprocess.nextTick(), the queue will never be empty, and you’ll never get to the next phase, which causes I/O starvation (inability to poll). - If you recursively call
setImmediate(), the next callback added will be executed in the next loop iteration, so the event loop will not be blocked. - And then there’s the impossible
process.nextTick(), even the great mafintosh asked this on twitter last July: “Does anyone have a good code example of when to use setImmediate instead of nextTick?” LOL
Warning!
You may have read a book that teaches you about “how to use process.nextTick() to split long-running tasks”. Since Node.js has modified the behavior of process.nextTick(), don't try what the book tells you! The event loop will be blocked by the long-running task! The split sub-tasks are still queued in the same phase and executed synchronously, which means they're as good as unsplit! You’ll do better to split them with setImmediate().
From this day on, don’t be misled by the name. Don't ever think that process.nextTick can schedule your task for the next tick. That is just asking for trouble! Here’s the official document’s recommendation:
We recommend developers use
setImmediate()in all cases because it's easier to reason about (and it leads to code that's compatible with a wider variety of environments, like browser JS.)
Node.js Event Loop
The Node official documentation mentions that process.nextTick is not part of the event loop phases in libuv. You can think about it this way: the event loop in the node is a wrapper on the low level libuv. Inside this wrapper, but outside of libuv, there are other things to process, which are process.nextTick and the Promise microtask. So when we talk about the node event loop, we mean the event loop as a whole at the level of the node, not just an instance of event loop in libuv.
In my other blog post, Looking at exports and module.exports through the node.js source code, I mentioned how the node core runs.
StartNodeInstance() -> CreateEnvironment() -> LoadEnvironment()
StartNodeInstance()
In StartNodeInstance(), uv_run() is called, and it's called inside a do while loop. This is where the node level event loop is:
{
SealHandleScope seal(isolate);
bool more;
do {
v8::platform::PumpMessageLoop(default_platform, isolate);
more = uv_run(env->event_loop(), UV_RUN_ONCE);
if (more == false) {
v8::platform::PumpMessageLoop(default_platform, isolate);
EmitBeforeExit(env);
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env->event_loop());
if (uv_run(env->event_loop(), UV_RUN_NOWAIT) != 0)
more = true;
}
} while (more == true);
}
CreateEnvironment()
When creating an environment, we need to pass a pointer that points to the uv_loop_t structure. This tells us that every instance of Node has its own event loop. During the creating process, part of the code is initializing in each phase.
Environment* CreateEnvironment(Isolate* isolate,
uv_loop_t* loop,
// ...
const char* const* exec_argv) {
// ...
uv_check_init(env->event_loop(), env->immediate_check_handle());
uv_unref(reinterpret_cast<uv_handle_t*>(env->immediate_check_handle()));
uv_idle_init(env->event_loop(), env->immediate_idle_handle());
uv_prepare_init(env->event_loop(), env->idle_prepare_handle());
uv_check_init(env->event_loop(), env->idle_check_handle());
uv_unref(reinterpret_cast<uv_handle_t*>(env->idle_prepare_handle()));
uv_unref(reinterpret_cast<uv_handle_t*>(env->idle_check_handle()));
// ...
return env;
}
startup.processNextTick() (/src/node.js)
Here, we only have to pay attention to the nextTickQueue at the beginning and process.nextTick(). This method simply adds the registered callbacks to the queue. When _tickCallback() is called, every callback in the queue is executed. When that’s all done, the next step is to call _runMicroTasks() to continue to process promises. If you want to learn more about microtasks, you can take a look at Tasks, microtasks, queues and schedules written by a Google engineer, Jake Archibald. He also included a little test about order of execution of a piece of code…LOL.
To sum it up, what I’m trying to say is that process.nextTick() and microtasks take the highest priority in asynchronous code. They are executed before the end of every phase. (Again, not every tick!)
startup.processNextTick = function() {
var nextTickQueue = []; // Callbacks are added to this queue!!
var pendingUnhandledRejections = [];
var microtasksScheduled = false;
var _runMicrotasks = {};
// ...
process.nextTick = nextTick; // nextTick function below
// ...
// process._setupNextTick is in node.cc. I think once you get the point across, there's no need to go deeper.
const tickInfo = process._setupNextTick(_tickCallback, _runMicrotasks);
_runMicrotasks = _runMicrotasks.runMicrotasks;
// ...
function _tickCallback() {
var callback, args, tock;
do {
while (tickInfo[kIndex] < tickInfo[kLength]) {
// callbacks are dug out of the queue to be executed one by one
tock = nextTickQueue[tickInfo[kIndex]++];
callback = tock.callback;
args = tock.args;
if (args === undefined) {
nextTickCallbackWith0Args(callback);
} else {
switch (args.length) {
case 1:
nextTickCallbackWith1Arg(callback, args[0]);
// ...
}
}
if (1e4 < tickInfo[kIndex])
tickDone();
}
tickDone();
// callback functions of process.nextTick finishes, then, promise microtasks
_runMicrotasks();
emitPendingUnhandledRejections();
} while (tickInfo[kLength] !== 0);
}
// ...
function nextTick(callback) {
var args;
if (arguments.length > 1) {
args = [];
for (var i = 1; i < arguments.length; i++)
args.push(arguments[i]);
}
// store the callbacks along with its aruments in an object and push it into the queue
nextTickQueue.push(new TickObject(callback, args));
tickInfo[kLength]++;
}
// ...
};
At this point I think you’ve got the gist of it. Since there's so much source code, I’ll leave it to the curious to dig into it themselves.
If you look at the “nextTick” of nextTickQueue, you may be misled to think that it is executed in the next loop iteration. In fact, the callback functions in this queue will execute before the event loop prepares for phase transition. About the ambiguity of the naming of nextTick and setImmediate, the official documentation mentions this as well:
In essence, the names should be swapped.
process.nextTick() fires more immediately thansetImmediate()but this is an artifact of the past which is unlikely to change. Making this switch would break a large percentage of the packages on npm.
If you've gotten to this point without falling asleep, mad props to you!
Now, don't get mad, but we’re finally getting to our other topic: the event emitter!
Trust me, this one will be over before you know it. Read the next article here
This post was translated to English by Codementor’s content team. Here’s the original Chinese post by Simen Li.
Thanks for nice post.
Just want to be clearer on the kick-in of next tick.
As you cited “A tick takes as long as it takes for one event loop iteration, where every callback in the queues has been executed synchronously and in order”, it could be reasoned that the callback scheduled by process.nextTick() should be run at the and of the loop iteration, i.e. when next tick would occur, rather than at the end of the current phase and before the next phase. Am I right ?