
Build Blazing Fast REST Api using Django + Elasticsearch + Haystack
Search is a most important part of your website and a fast search is even more important. While user can't find things manually or running out of time, he uses the search & having a slow search can frustrate your user even more
In this Blog, we will make a REST API using
Here we are building the API for a movie app just like netflix or any other streaming website. if you directly want to checkout the code then jump here.
So Far ElasticSearch is the best search engine for searching text and it is very fast. It is also very easy to integrate with Django. While Searching through the app, you can also filter the results by year, genre, and rating. If you make this Same functionality using Default Django Search like using icontains or contains then it will take a lot of time to search and filter the results as we are hitting the Database & hitting the DB costs you time. But with ElasticSearch, it is very fast as instead of hitting the Database, we are hiting the elastic search data which is a indexed data and so, much faster to query than the regular DB.
I will not be going deep down as several blogs can be written for every tech used in this tutorial.
Before moving ahead, I assume you have some basic knowledge of
if you meet above requirements, then you are good to go & if not, let's go ahead and you will understand how things navigate when making such type of functionality.🙂
So let's Start - 
To save time, I have already made a git repo with complete instructions. I will be doing a go throw of how i made this with enough explanation.
git clone https://github.com/selftaughtdev-me/movie-search-api.git
sudo apt update -y sudo apt install libpq-dev postgresql postgresql-contrib -y
sudo service postgresql start sudo add-apt-repository ppa:deadsnakes/ppa sudo apt update -y
sudo apt-get install apt-transport-https
sudo apt install python3.8 python3.8-dev python3.8-venv build-essential -y sudo apt install openjdk-11-jdk openjdk-11-jre -y curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
sudo apt update
sudo apt install elasticsearch -y
sudo service elasticsearch start
sudo service elasticsearch status
Above, we install Elastic Search along with Java which is required to run this. While you guys maybe mostly using Relational Databases like Postgres or mysql which stores the data in table form. Elastic Search is a open source NoSQL database which stores the data in the JSON format. Also the Data is indexed and very fast to query if you compared the search time with other Databases.
Elastic search is open source but there are services which you may need to pay just like you pay for Mongodb when using their paid services. Now here., we are using the Postgres for storing the movie data & elastic search for storing a copy of movie data but that data will be indexed data like i said above.
sudo -u postgres psql
CREATE DATABASE django_flix;
CREATE USER django_flix_user WITH PASSWORD 'html_programmer';
ALTER ROLE django_flix_user SET client_encoding TO 'utf8';
ALTER ROLE django_flix_user SET default_transaction_isolation TO 'read committed';
ALTER ROLE django_flix_user SET timezone TO 'UTC';
GRANT ALL PRIVILEGES ON DATABASE django_flix TO django_flix_user;
\q
python3.8 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install wheel
pip install -r requirements.txt
./manage.py migrate
./manage.py createsuperuser
Wait.. did you change directory to project folder. if not please do.😁
Now we need to generate a lot of data to test our api. In your terminal, type
./manage.py generate_test_data 1000000

- 💡If you can't wait for large data creation, here is a tip. To Save Time, I only tried this API with 600K records, which took a lot of time. So I would suggest to try with just 5000 record & run this command in different terminal windows to generate data in parallel.
./manage.py runserver
http://localhost:8000/api/?q=t
http://localhost:8000/api/search/?q=t&facets=year:1983
http://localhost:8000/api/search/?q=t&facets=year:1983,genre:rise
📌You Can ignore this ElasticSearch Warning while you are not using it in production

📌The Generated Data is not realistic.. it's just for demo purpose. But as you can see in debug panel on the right side, the SQL count is 0 which means it is not hitting the database. It is directly hitting the ElasticSearch
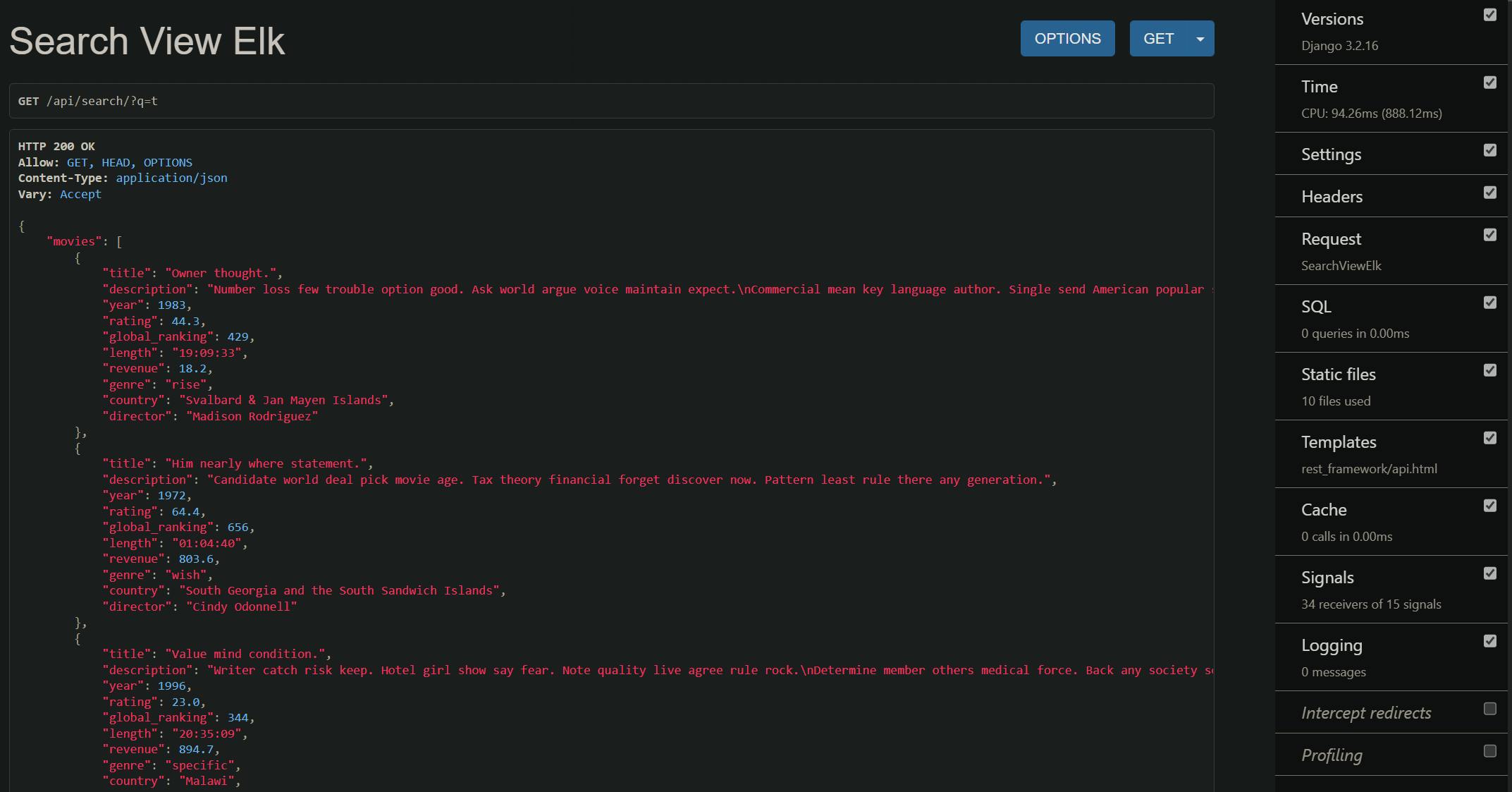
Now after you have tested the API, Let's see how it's working. open settings.pyDjango Haystack is a django package that provides a SearchQuerySet & many other Api which you can use to efficiently communicate with ElasticSearch and search you data.
INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", "django_extensions", "rest_framework", "haystack", "apps.core", "debug_toolbar",
]
HAYSTACK_CONNECTIONS = { "default": { "ENGINE": "haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine", "URL": "http://127.0.0.1:9200/", "INDEX_NAME": "django_flix", },
} HAYSTACK_SIGNAL_PROCESSOR = "haystack.signals.RealtimeSignalProcessor"
After this, headover to core/search_indexes.py. this file contains like a mapping. like how you want to index you SQL DB's Data into the ElasticSearch.
Here is how it's structured -
from haystack import indexes
from .models import Movie class MovieIndex(indexes.SearchIndex, indexes.Indexable): id = indexes.IntegerField(model_attr="id") text = indexes.CharField(document=True, use_template=True) title = indexes.CharField(model_attr="title") description = indexes.CharField(model_attr="description") year = indexes.IntegerField(model_attr="year") rating = indexes.FloatField(model_attr="rating") global_ranking = indexes.IntegerField(model_attr="global_ranking") length = indexes.CharField(model_attr="length", faceted=True) revenue = indexes.FloatField(model_attr="revenue", faceted=True) genre = indexes.CharField(model_attr="genre", faceted=True) country = indexes.CharField(model_attr="country", faceted=True) director = indexes.CharField(model_attr="director", faceted=True) def get_model(self): return Movie def prepare_director(self, obj): return obj.director.name def prepare_genre(self, obj): return obj.genre.name def prepare_country(self, obj): return obj.country.name def index_queryset(self, using=None): return self.get_model().objects.all()
Some things to note here -
Facet -> Go to amazon & when you search any product, you will see some filters on the left side. these filters are actually facet fields.
faceted=True -> whichever field you type in this kwarg, that field will then can be used for filtering purpose. So when searching, you can search like this 👇
model_attr -> The model field, which you are referring to map.
base_api_url.com/?q=some_query&facets=year:1983,genre:rise
Now move to core/views.py & the first view you saw there is responsible for rendering this data.
class SearchViewElk(APIView, LimitOffsetPagination): default_limit = 10 serializer_class = MovieHayStackSerializer def get(self, request): query = request.GET.get("q", None) highlight = request.GET.get("highlight", None) facets = request.GET.get("facets", None) sqs = SearchQuerySet().models(Movie) if query: query_list = query.split(" ") qs_item = reduce( operator.and_, (Q(text__contains=item) for item in query_list) ) sqs = sqs.filter(qs_item) if highlight: sqs = sqs.highlight() if facets: sqs = self.filter_sqs_by_facets(sqs, facets) page = self.paginate_queryset(sqs, request, view=self) movie_serializer = self.serializer_class(page, many=True) facets = self.get_facet_fields(sqs) summary = self.prepare_summary(sqs) data = {"movies": movie_serializer.data, "facets": facets, "summary": summary} return Response(data, status=HTTP_200_OK) def filter_sqs_by_facets(self, sqs, facets): facet_list = facets.split(",") for facet in facet_list: facet_key, facet_value = facet.split(":") sqs = sqs.narrow(f"{facet_key}:{facet_value}") return sqs def get_facet_fields(self, sqs): facet_fields = ( sqs.facet("year") .facet("rating") .facet("global_ranking") .facet("length") .facet("revenue") .facet("country") .facet("genre") ) return facet_fields.facet_counts() def prepare_summary(self, sqs): summary = { "total": sqs.count(), "next_page": self.get_next_link(), "previous_page": self.get_previous_link(), } return summary
Even though I mentioned proper comments, but there are some terms new to you.
SearchQuerySet() -> The SearchQuery class acts as an intermediary between SearchQuerySet’s abstraction and SearchBackend’s actual search. Given the metadata provided by SearchQuerySet, SearchQuery builds the actual query and interacts with the SearchBackend on SearchQuerySet’s behalf. Any SearchQuerySet obj is mostly same as a Django Queryset Object. So that means that you can use filter and other operations, like you do using Django Model QuerySet.
sqs.highlight() -> This will make the results contains a highlighted key in Json Response and the highlighted text will be enclosed in <em> tags. you can also customise it to a custom class & later on do the styling on fronted side for given class.
sqs.facet('some_facetable_field') -> Get all the possible facets like if you facet over year field which also have faceted=true in search_indexes.py. you will get an object which contains info like how much movies created every particular year.
.facet_counts() -> Since sqs.facet returns a object, we need to get values from this object & this attribute did that job.
There is also a serializer to convert the SearchQuerySet of Haystack into json.
from drf_haystack.serializers import HaystackSerializer from .search_indexes import MovieIndex class MovieHayStackSerializer(HaystackSerializer): class Meta: index_classes = [MovieIndex] fields = [ "title", "description", "year", "rating", "global_ranking", "length", "revenue", "genre", "country", "director",
]

And Now you have your API ready. you can do other customisation like AutoQuery which allows to search same like google. that means that if you add - in front of any query than the results matching the query will be excluded. and there are other too many customisation options which can check out on documentation.
This is my first blog & I know it's not much understandable but i will try to improve. 😁
Helpful Links
Disclaimer - I am not an expert & still learning. So, there may be some things which i may missed out or may be wrongly explained. As I got any comment about mistakes or figured out somewhere then i will correct it in blog.