
Scalars, Vectors, Matrices and Tensors with Tensorflow 2.0
Scalars: are just a single number. For example temperature, which is denoted by just one number.
Vectors: are an array of numbers. The numbers are arranged in order and we can identify each individual number by its index in that ordering. We can think of vectors as identifying points in space, with each element giving the coordinate along a different axis. In simple terms, a vector is an arrow representing a quantity that has both magnitude and direction wherein the length of the arrow represents the magnitude and the orientation tells you the direction. For example wind, which has a direction and magnitude.
Matrices: A matrix is a 2D-array of numbers, so each element is identified by two indices instead of just one. If a real valued matrix A has a height of m and a width of n, then we say that A in Rm x n. We identify the elements of the matrix as A_(m,n) where m represents the row and n represents the column.

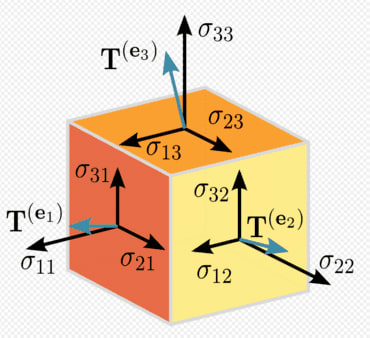
Tensors: In the general case, are an array of numbers arranged on a regular grid with a variable number of axes is knows as a tensor. We identify the elements of a tensor A at coordinates(i, j, k) by writing A_(i, j, k). But to truly understand tensors, we need to expand the way we think of vectors as only arrows with a magnitude and direction. Remember that a vector can be represented by three components, namely the x, y and z components (basis vectors). If you have a pen and a paper, let's do a small experiment, place the pen vertically on the paper and slant it by some angle and now shine a light from top such that the shadow of the pen falls on the paper, this shadow, represents the x component of the vector "pen" and the height from the paper to the tip of the pen is the y component. Now, let's take these components to describe tensors, imagine, you are Indiana Jones or a treasure hunter and you are trapped in a cube and there are three arrows flying towards you from the three faces (to represent x, y, z axis) of the cube 😬, I know this will be the last thing you would think in such a situation but you can think of those three arrows as vectors pointing towards you from the three faces of the cube and you can represent those vectors (arrows) in x, y and z components, now that is a rank 2 tensor (matrix) with 9 components. Remember that this is a very very simple explanation of tensors. Following is a representation of a tensor:
We can add matrices to each other as long as they have the same shape, just by adding their corresponding elements:
C = A + B where C_(i,j) = A_(i,j) + B_(i,j)
If you have trouble viewing the equations in the browser you can also read the chapter in Jupyter nbviewer in its entirety. If not, let's continue.
In tensorflow a:
- Rank 0 Tensor is a Scalar
- Rank 1 Tensor is a Vector
- Rank 2 Tensor is a Matrix
- Rank 3 Tensor is a 3-Tensor
- Rank n Tensor is a n-Tensor
# let's create a ones 3x3 rank 2 tensor
rank_2_tensor_A = tf.ones([3, 3], name='MatrixA')
print("3x3 Rank 2 Tensor A: \n{}\n".format(rank_2_tensor_A)) # let's manually create a 3x3 rank two tensor and specify the data type as float
rank_2_tensor_B = tf.constant([[1, 2, 3], [4, 5, 6], [7, 8, 9]], name='MatrixB', dtype=tf.float32)
print("3x3 Rank 2 Tensor B: \n{}\n".format(rank_2_tensor_B)) # addition of the two tensors
rank_2_tensor_C = tf.add(rank_2_tensor_A, rank_2_tensor_B, name='MatrixC')
print("Rank 2 Tensor C with shape={} and elements: \n{}".format(rank_2_tensor_C.shape, rank_2_tensor_C)) 3x3 Rank 2 Tensor A:
[[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]] 3x3 Rank 2 Tensor B:
[[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] Rank 2 Tensor C with shape=(3, 3) and elements:
[[2. 3. 4.] [5. 6. 7.] [8. 9. 10.]]
# Let's see what happens if the shapes are not the same
two_by_three = tf.ones([2, 3])
try: incompatible_tensor = tf.add(two_by_three, rank_2_tensor_B)
except: print("""Incompatible shapes to add with two_by_three of shape {0} and 3x3 Rank 2 Tensor B of shape {1} """.format(two_by_three.shape, rank_2_tensor_B.shape)) Incompatible shapes to add with two_by_three of shape (2, 3) and 3x3 Rank 2 Tensor B of shape (3, 3)
We can also add a scalar to a matrix or multiply a matrix by a scalar, just by performing that operation on each element of a matrix:
D = a.B + c where D_(i,j) = a.B_(i,j) + c
# Create scalar a, c and Matrix B
rank_0_tensor_a = tf.constant(2, name="scalar_a", dtype=tf.float32)
rank_2_tensor_B = tf.constant([[1, 2, 3], [4, 5, 6], [7, 8, 9]], name='MatrixB', dtype=tf.float32)
rank_0_tensor_c = tf.constant(3, name="scalar_c", dtype=tf.float32) # multiplying aB
multiply_scalar = tf.multiply(rank_0_tensor_a, rank_2_tensor_B)
# adding aB + c
rank_2_tensor_D = tf.add(multiply_scalar, rank_0_tensor_c, name="MatrixD") print("""Original Rank 2 Tensor B: \n{0} \n\nScalar a: {1}
Rank 2 Tensor for aB: \n{2} \n\nScalar c: {3} \nRank 2 Tensor D = aB + c: \n{4}
""".format(rank_2_tensor_B, rank_0_tensor_a, multiply_scalar, rank_0_tensor_c, rank_2_tensor_D)) Original Rank 2 Tensor B:
[[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] Scalar a: 2.0
Rank 2 Tensor for aB:
[[2. 4. 6.] [8. 10. 12.] [14. 16. 18.]] Scalar c: 3.0
Rank 2 Tensor D = aB + c:
[[5. 7. 9.] [11. 13. 15.] [17. 19. 21.]]
One important operation on matrices is the transpose. The transpose of a matrix is the mirror image of the matrix across a diagonal line, called the main diagonal. We denote the transpose of a matrix A as AT and is defined as such: AT (i, j) = A(j, i)
# Creating a Matrix E
rank_2_tensor_E = tf.constant([[1, 2, 3], [4, 5, 6]])
# Transposing Matrix E
transpose_E = tf.transpose(rank_2_tensor_E, name="transposeE") print("""Rank 2 Tensor E of shape: {0} and elements: \n{1}\n
Transpose of Rank 2 Tensor E of shape: {2} and elements: \n{3}""".format(rank_2_tensor_E.shape, rank_2_tensor_E, transpose_E.shape, transpose_E)) Rank 2 Tensor E of shape: (2, 3) and elements:
[[1 2 3] [4 5 6]] Transpose of Rank 2 Tensor E of shape: (3, 2) and elements:
[[1 4] [2 5] [3 6]]
In deep learning we allow the addition of matrix and a vector, yielding another matrix where C_(i, j) = A_(i, j) + b_(j). In other words, the vector b is added to each row of the matrix. This implicit copying of b to many locations is called broadcasting
# Creating a vector b
rank_1_tensor_b = tf.constant([[4.], [5.], [6.]])
# Broadcasting a vector b to a matrix A such that it yields a matrix F = A + b
rank_2_tensor_F = tf.add(rank_2_tensor_A, rank_1_tensor_b, name="broadcastF") print("""Rank 2 tensor A: \n{0}\n \nRank 1 Tensor b: \n{1}
\nRank 2 tensor F = A + b:\n{2}""".format(rank_2_tensor_A, rank_1_tensor_b, rank_2_tensor_F)) Rank 2 tensor A:
[[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]] Rank 1 Tensor b:
[[4.] [5.] [6.]] Rank 2 tensor F = A + b:
[[5. 5. 5.] [6. 6. 6.] [7. 7. 7.]]
This is section two of the Chapter on Linear Algebra with Tensorflow 2.0 of the Book Deep Learning with Tensorflow 2.0.
You can read this section and the following topics:
02.01 — Scalars, Vectors, Matrices and Tensors
02.02 — Multiplying Matrices and Vectors
02.03 — Identity and Inverse Matrices
02.04 — Linear Dependence and Span
02.05 — Norms
02.06 — Special Kinds of Matrices and Vectors
02.07 — Eigendecomposition
02.08 — Singular Value Decomposition
02.09 — The Moore-Penrose Pseudoinverse
02.10 — The Trace Operator
02.11 — The Determinant
02.12 — Example: Principal Components Analysis
at Deep Learning With TF 2.0: 02.00- Linear Algebra. You can get the code for this article and the rest of the chapter here. Links to the notebook in Google Colab and Jupyter Binder is at the end of the notebook.