
Python Optimization: How it Can Make You a Better Programmer
Codementor Python expert and Stack Overflow legend Martijn Pieters joined us for an Office Hour session to give us a quick tutorial about Python optimization.
The text below is a summary done by the Codementor team and may vary from the original video and if you see any issues, please let us know!
A Common Pitfall Beginning Python Coders Can Make
First of all, everything in Python is an object, which, as opposed to C or any other programming language, includes numbers. In particular, integers are also objects, and every time a Python coder uses an integer, Python has to create the object.
However, in order to speed things up and save coders from the process of constantly creating numbers, what should be noted is that commonly used integers between -5 and 256 are cached in Python. Thus, every time a Python programmer asks for a number such as 5, Python already has the object and uses it every time the number 5 is called. In other words, the integers between -5 and 256 are singletons, which means they are always the same single object and there is only one copy of each number. This is possible because integers are immutable, as one cannot change their value.
However, this process of using cached integers also creates the potential for beginning Python coders to become confused about the two comparison operators in Python: is (identity) and == (equality). Is tests two references to verify whether they point to the same object, while == compares the value of two objects that may or may not be the same thing.
“Identity is not the same thing as equality”
One of the most common mistake Python beginners make is to confuse is with equality, and because commonly used integers are cached, they might not realize their error for a good amount of time.
Below are two examples to illustrate the problem:
//Example 1//

In this example, foo == bar comes out true because they are of the same value. However, foo is bar also turns out true because Python gives the same exact object 42 for both foo and bar instead of creating another one. Thus, as the example shows, if you use the function id() to retrieve the memory address of foo and bar’s unique identifiers, they both point to the same address. Beginning Python programmers might not notice they have made a mistake and come to expect is to be the same thing as equality.
Yet, the problem arises when larger numbers are used.
//Example 2//

As only integers between -5 and 256 are cached, 10 * 1000 is 10000 turns out false as Python creates new objects for both 10 * 1000 and 10,000. This can be quite confusing to some Python beginners, so they need to be aware that is means identity and == means equality.
Interning Strings for Efficiency
The Python interpreter works a lot with strings, and like small integers, strings can also be reused by Python through a slightly different technique called interning. When a new string is created, the Python interpreter can choose whether or not to store a cached copy of that string. This happens under certain circumstances, in particular for identifiers.
Therefore, if a string starts with a letter or an underscore and only contains letters, underscores, or numbers, Python will intern the string and create a hash for it. As most things in Python are dictionaries, Python has to do a lot of lookups for identifiers, and by interning identifier strings the lookup process can be sped up quite a bit. In other words, identifiers are stored in a table, and Python creates a hash from the string object for future lookups. Such optimization occurs during compile time, and string literals that look like identifiers will also be interned.
Python programmers can make use of interning when using their own string to look up slots. For example, it could be advantageous to use interning when working with a large text-processing program that requires much replacements or lookups and responds to a lot of network messages with mappings. Strings read from a file or network connection aren’t interned (though string literals may have been interned), but you can use the function intern() to create your own interned copy of such strings.
Peephole Optimization
To save you from creating similar objects every time the code is loaded, Python stores them as literals.
//Example 3//
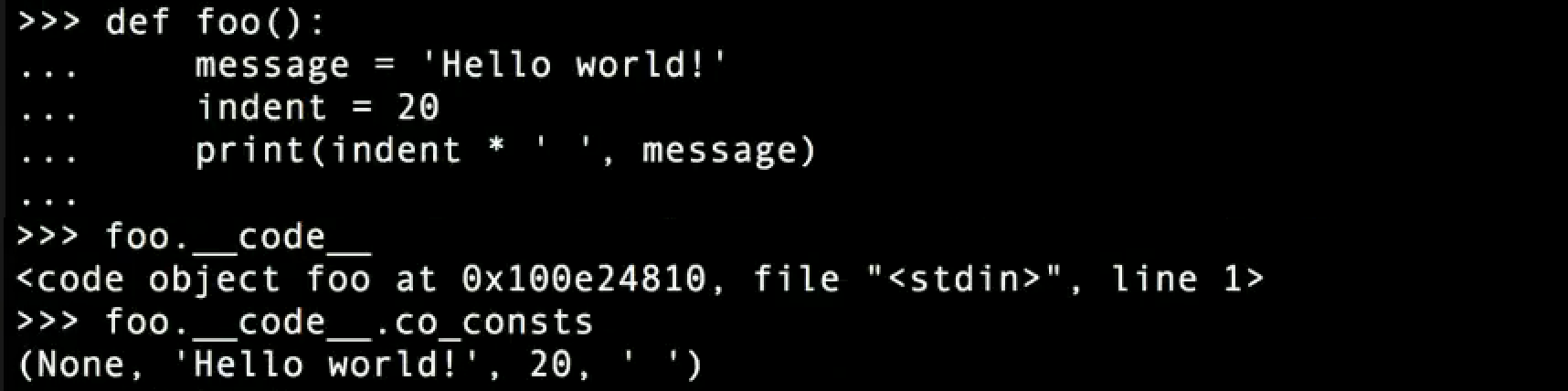
In this code, two literals are used—a string literal and an integer literal. There is now a code object assigned to “foo” and a constant associated with it. Thus, in the example above, none, hello world, space (‘ ’), and the number 20 are all stored as constants.
Apart from storing constants, Python has several more optimization tricks, such as simplifying several types of expressions, and replacing certain mutable objects with immutable objects.
The expressions Python simplifies are calculations in the code, so programmers can store functions as calculations, as Python’s peephole optimizer will store the result of the expression instead of re-calculating each time the function is used. Basically, anything that is immutable and has an expression is pre-calculated compile time and stored, which includes any type of sequence, such as strings. If a string consists of multiple pieces and is put together with a class, it will be replaced by the final result. However, anything longer than 20 characters will be ignored.
//Example 4//

In the example above, “duration” and “neener” have both been expanded into the result, so Python will load 864,000 every time “duration” is referred to and Python will load neenerneenerneener for the expression “neener”. However, big_constant’s tuple has not been expanded because the peephole optimizer is being smart about space. A tuple of 3000 elements will make a bytecode file unusually large, which is why a sequence can be multiplied by at most 20 times. Thus, the peephole optimization has limits, as strings often exceed 20 characters. Nonetheless, the peephole optimization is still quite useful in saving programmers from having to worry about all the constants they may use.
Furthermore, as mentioned above, the peephole optimization can also replace mutables with immutables. A mutable set literal can be changed in principle, as it is really an immutable object, like a list object.

In the example in this slide, an in test is used to verify the membership of a literal, and Python replaces the set with a frozen set to be stored away in the code. Thus, one can and should make use of sets whenever there is a need to test for membership, as the test has a constant cost operation. In other words, no matter how large the set is, Python will always take the same amount of time to validate membership, and this will always be faster than testing against a tuple or list.
Furthermore, Python does the same thing to lists. If a literal list object is put in a membership test, Python will replace it with an actual tuple constant in the code, much like the example below.

To see what happens with code optimization and what Python does, one can use the disassembly tool. The module gives back the original bytecode or piece of code, which can be passed in a function to see what the code object looks like.

It is important to note that only literals work. If the set or list is not a literal, the optimization does not take place. However, this does not apply to lists such as tuples, as a tuple can be created with a literal syntax with the parentheses, and therefore can be stored as a single, constant object.