
Web Scraping in Python using Scrapy
When I first started working in industry, one of the things I quickly realized is sometimes you have to gather, organize, and clean your own data. For this tutorial, we will gather data from a crowdfunding website called FundRazr. Like many websites, the site has its own structure, form, and has tons of accessible useful data, but it is hard to get data from the site as it doesn’t have a structured API. In result, we will web scrape the site to get that unstructured website data and put into an ordered form to build our own dataset.
Web Scraping (Scrapy) using Python
In order to scrape the website, we will use Scrapy. In short, Scrapy is a framework built to build web scrapers more easily and relieve the pain of maintaining them. Basically, it allows you to focus on the data extraction using CSS selectors and choosing XPath expressions and less on the intricate internals of how spiders are supposed to work. This blog post goes a little beyond the great official tutorial from the scrapy documentation in the hopes that if you need to scrape something a bit harder, you can do it on your own. With that, lets get started. If you get lost, I recommend opening the video above in a separate tab.
Getting Started (Prerequisites)
If you already have anaconda and google chrome (or Firefox), skip to Creating a New Scrapy Project.
1. Install Anaconda (Python) on your operating system. You can either download anaconda from the official site and install on your own or you can follow these anaconda installation tutorials below.
| Operating System | Blog Post | Youtube Video |
|---|---|---|
| Mac | Install Anaconda on Mac | Youtube Video |
| Windows | Install Anaconda on Windows | Youtube Video |
| Ubuntu | Install Anaconda on Ubuntu | Youtube Video |
| All | Environment Management with Conda (Python 2 + 3, Configuring Jupyter Notebooks) | Youtube Video |
2. Install Scrapy (anaconda comes with it, but just in case). You can also install on your terminal (mac/linux) or command line (windows). You can type the following:
conda install -c conda-forge scrapy
3. Make sure you have Google chrome or Firefox. In this tutorial, I am using Google Chrome. If you don’t have google chrome, you can install it here using this link.
Creating a New Scrapy Project
1. Open a terminal (mac/linux) or command line (windows). Navigate to a desired folder (see the image below if you need help) and type
scrapy startproject fundrazr

scrapy startproject fundrazr
This makes a fundrazr directory with the following contents:
fundrazr project directory
Finding Good Start URLs using Inspect on Google Chrome (or Firefox)
In the spider framework, start_urls is a list of URLs where the spider will begin to crawl from, when no particular URLs are specified. We will use each element in the start_urls list as a means to get individual campaign links.
1. The image below shows that based on the category you choose, you get a different start url. The highlighted part in black are the possible categories of fundrazrs to scrape.
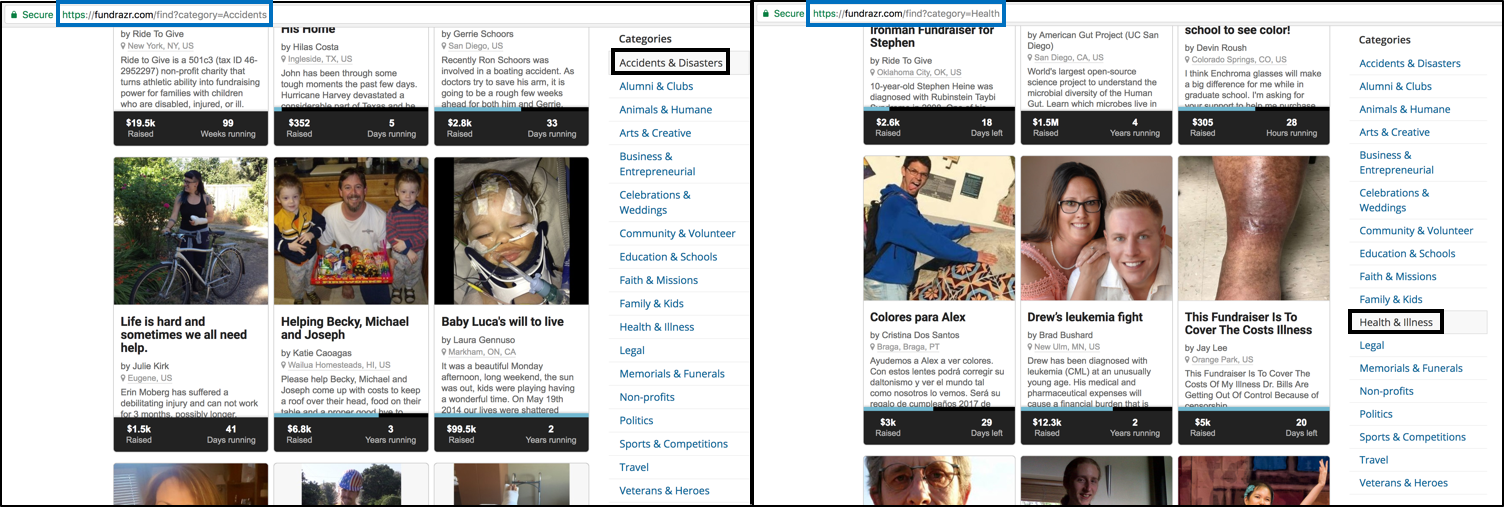
Finding a good first start_url
For this tutorial, the first in the list start_urls is:
https://fundrazr.com/find?category=Health
2. This part is about getting additional elements to put in the start_urls list. We are finding out how to go to the next page so we can get additional urls to put in start_urls.
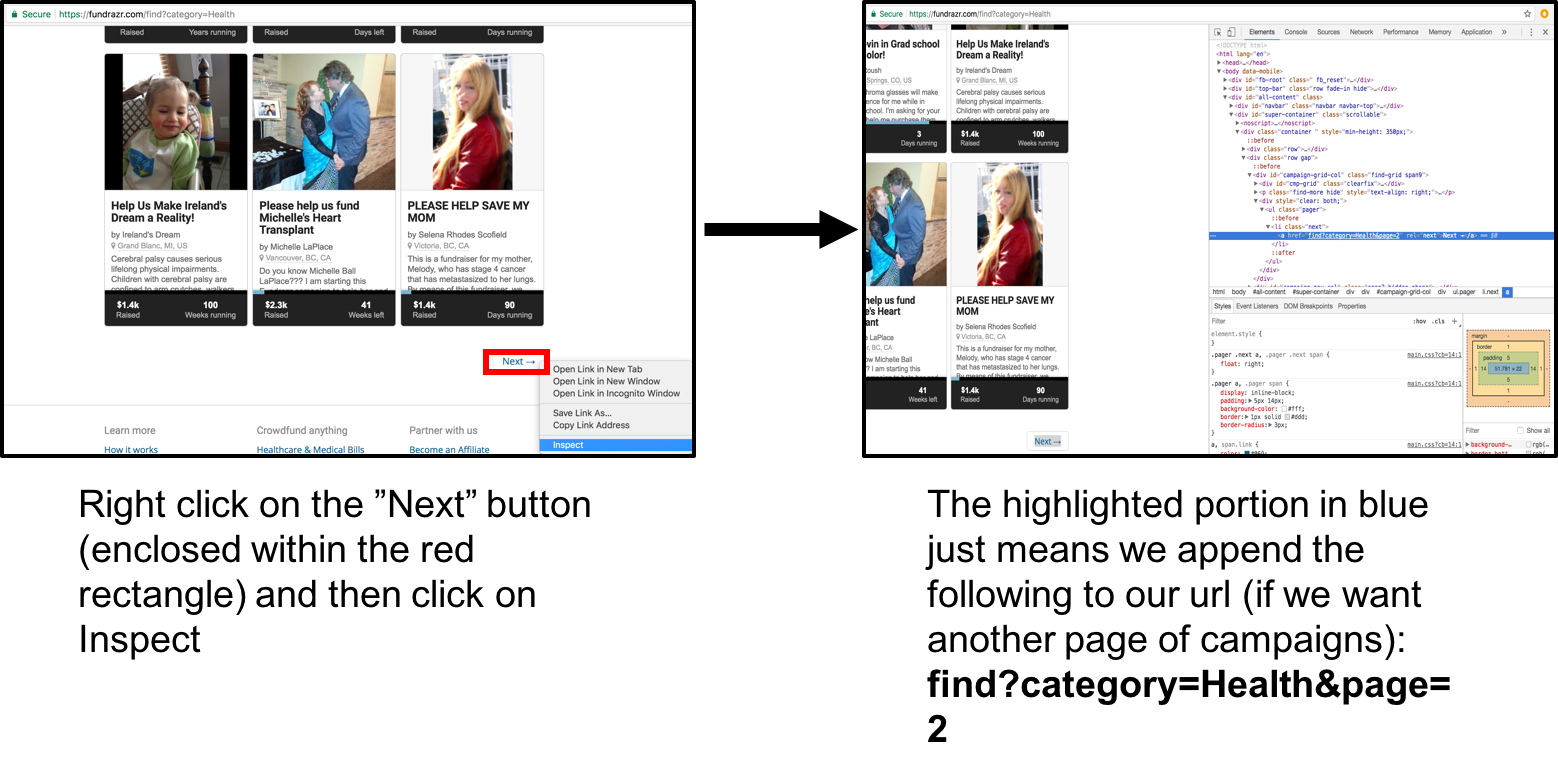
Getting additional elements to put in start_urls list by inspecting Next button
The second start url is: https://fundrazr.com/find?category=Health&page=2
The code below will be used in the code for the spider later in the tutorial. All it does is make a list of start_urls. The variable npages is just how many additional pages (after the first page) we want to get campaign links from.
start_urls = ["https://fundrazr.com/find?category=Health"]
npages = 2
# This mimics getting the pages using the next button.
for i in range(2, npages + 2 ):
start_urls.append("https://fundrazr.com/find?category=Health&page="+str(i)+"")
Scrapy Shell for finding Individual Campaign Links
The best way to learn how to extract data with Scrapy is using the Scrapy shell. We will use XPaths which can be used to select elements from HTML documents.
The first thing we will try and get the xpaths for are the individual campaign links. First we do inspect to see roughly where the campaigns are in the HTML.
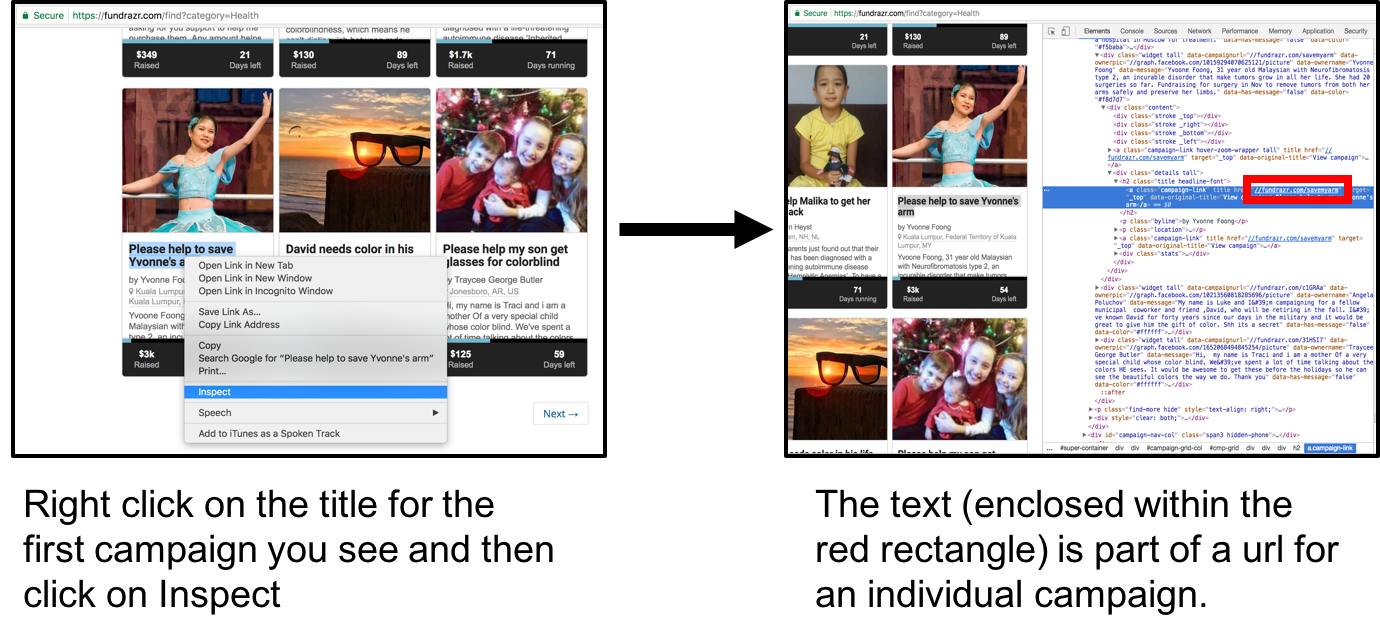
Finding links to individual campaigns
We will use XPath to extract the part enclosed in the red rectangle below.

The enclosed part is a partial url we will isolate
In terminal type (mac/linux):
scrapy shell 'https://fundrazr.com/find?category=Health'
In command line type (windows):
scrapy shell “https://fundrazr.com/find?category=Health"
Type the following into scrapy shell (to help understand the code, please see the video):
response.xpath("//h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href").extract()

There is a good chance you will get different partial urls as websites update over time
The code below is for getting all the campaign links for a given start url (more on this later in the First Spider section)
for href in response.xpath("//h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href"):
# add the scheme, eg http://
url = "https:" + href.extract()
Exit Scrapy Shell by typing exit().

exit scrapy shell
Inspecting Individual Campaigns
While we should previously worked on understanding the structure of where individual campaigns links are, this section goes over where things are on individual campaigns.
1. Next we go to an individual campaign page (see link below) to scrape (I should note that some of these campaigns are difficult to view)
https://fundrazr.com/savemyarm
2. Using the same inspect process as before, we inspect the title on the page
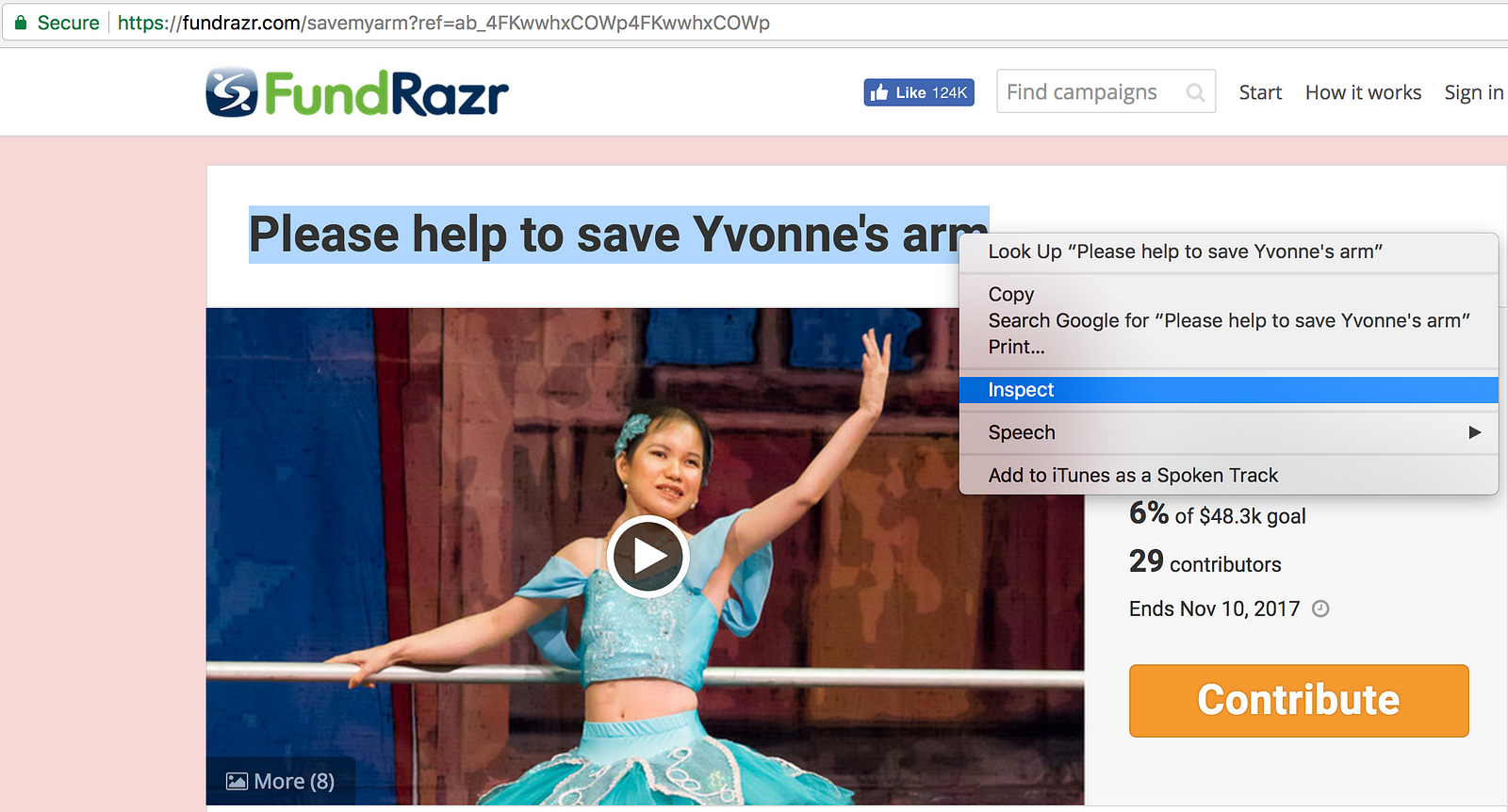
Inspect Campaign Title
3. Now we are going to use scrapy shell again, but this time with an individual campaign. We do this because we want to find out how individual campaigns are formatted (including finding out how to extract the title from the webpage).
In terminal type (mac/linux):
scrapy shell 'https://fundrazr.com/savemyarm'
In command line type (windows):
scrapy shell “https://fundrazr.com/savemyarm"
The code to get the campaign title is
response.xpath("//div[contains(@id, 'campaign-title')]/descendant::text()").extract()[0]

4. We can do the same for the other parts of the page.
amount Raised:
response.xpath("//span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()
goal:
response.xpath("//div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()").extract()
currency type:
response.xpath("//div[contains(@class, 'stats-primary with-goal')]/@title").extract()
campaign end date:
response.xpath("//div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap']/text()").extract()
number of contributors:
response.xpath("//div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract()
story:
response.xpath("//div[contains(@id, 'full-story')]/descendant::text()").extract()
url:
response.xpath("//meta[@property='og:url']/@content").extract()
5. Exit scrapy shell by typing:
exit()
Items
The main goal in scraping is to extract structured data from unstructured sources, typically, web pages. Scrapy spiders can return the extracted data as Python dicts. While convenient and familiar, Python dicts lack structure: it is easy to make a typo in a field name or return inconsistent data, especially in a larger project with many spiders (almost word for word copied from the great scrapy official documentation!).
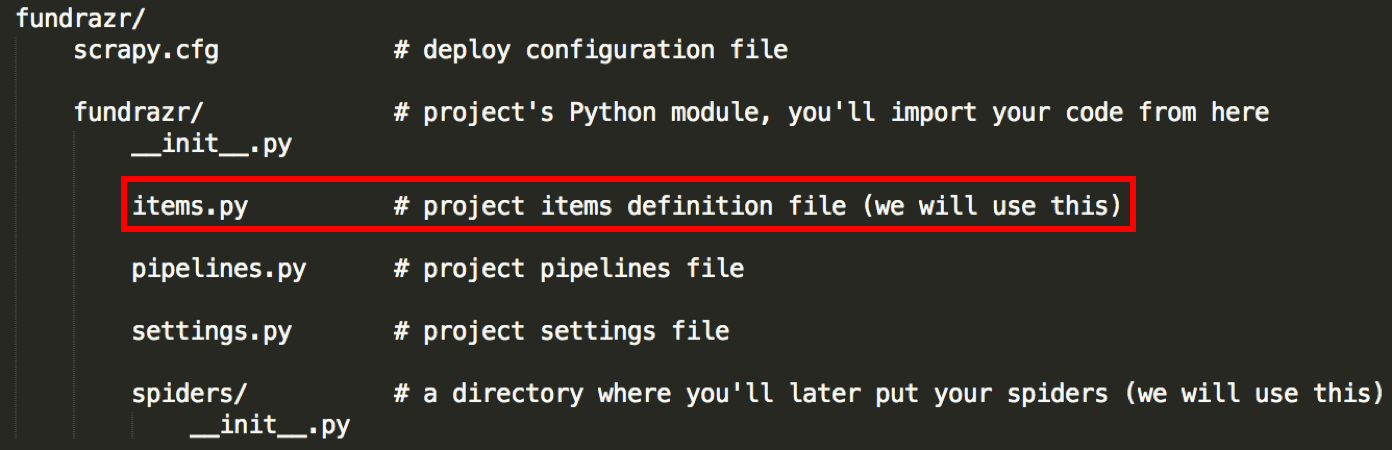
File we will be modifying
The code for items.py is here.
Save it under the fundrazr/fundrazr directory (overwrite the original iems.py file).
The item class (basically how we store our data before outputting it) used in this tutorial looks like this.
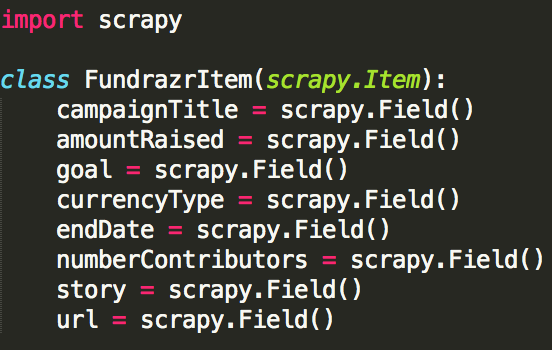
items.py code
The Spider
Spiders are classes that you define and that Scrapy uses to scrape information from a website (or a group of websites). The code for our spider is below.
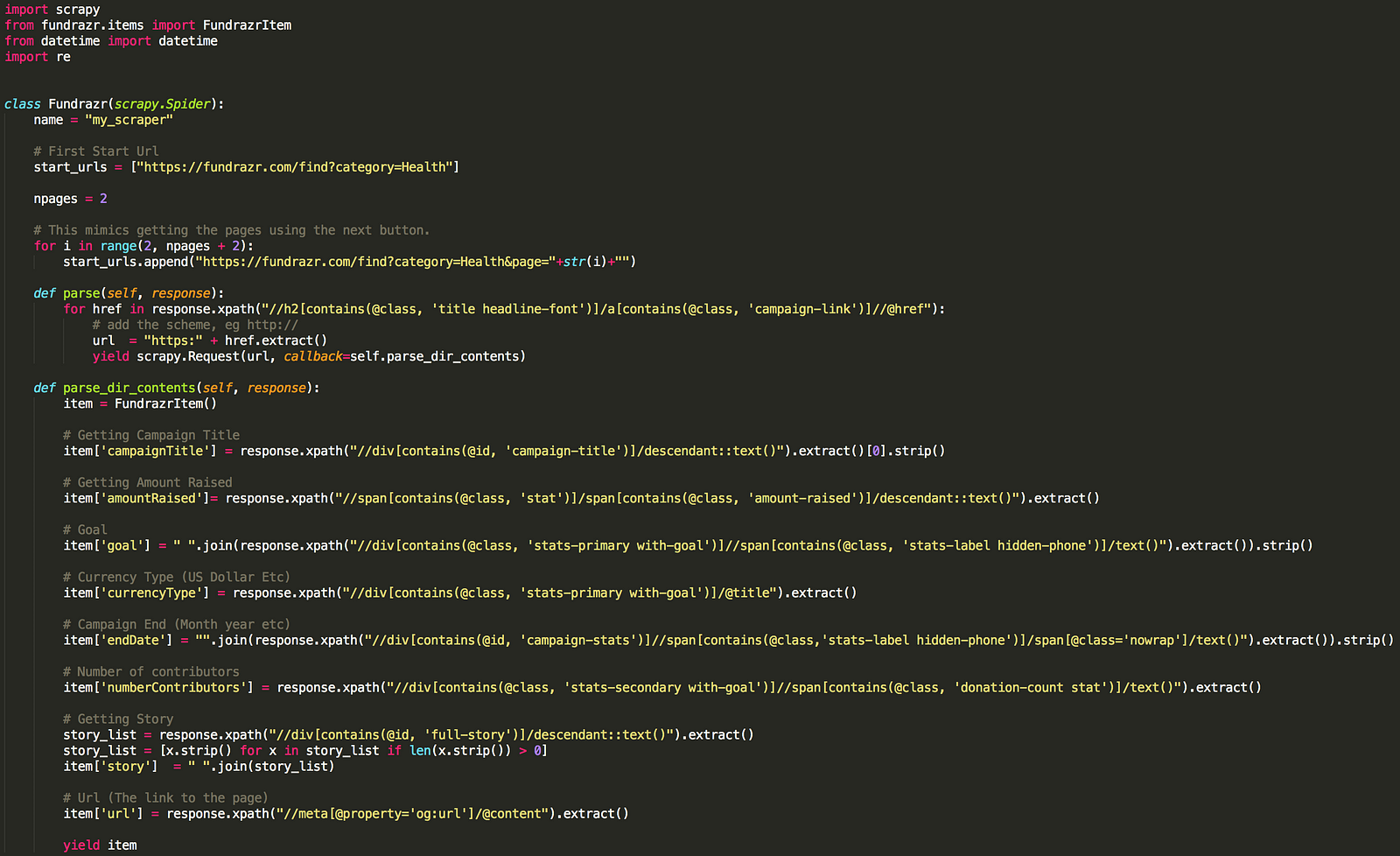
Fundrazr Scrapy Code
Download the code here.
Save it in a file named fundrazr_scrape.py under the fundrazr/spiders directory.
The current project should now have the following contents:
File we will be creating/adding
Running the Spider
1. Go to the fundrazr/fundrazr directory and type:
scrapy crawl my_scraper -o MonthDay_Year.csv
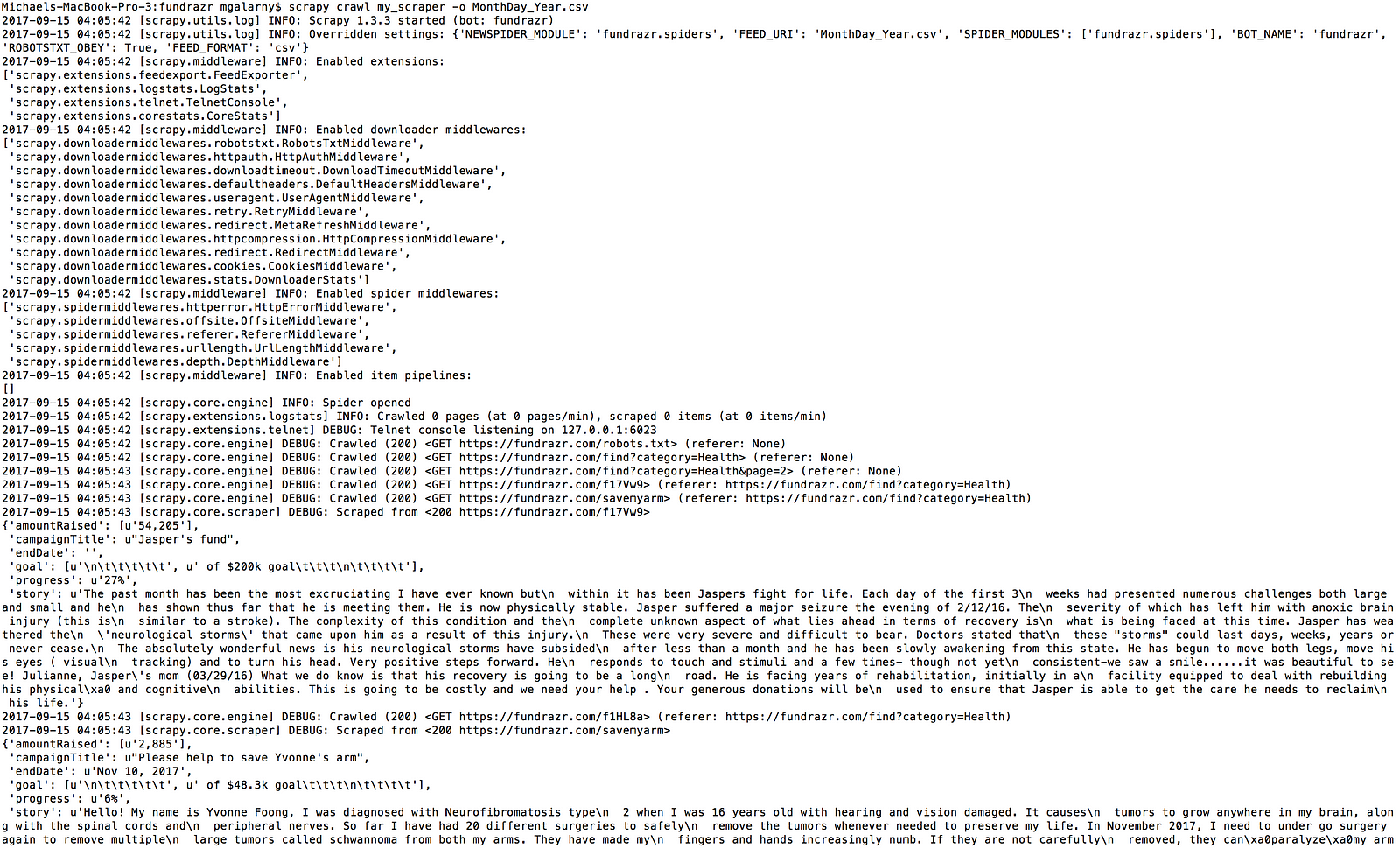
scrapy crawl my_scraper -o MonthDay_Year.csv
2. The data should be outputted in the fundrazr/fundrazr directory.
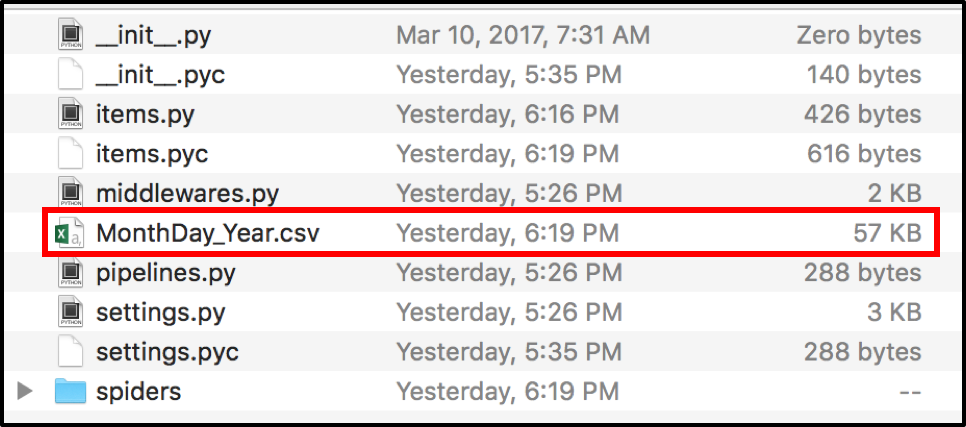
Data Output Location
Our Data
1. The data outputted in this tutorial should look roughly like the image below. The individual campaigns scraped will vary as the website is constantly updated. Also it is possible there will be spaces between each individual campaign as excel is interpreting the csv file.
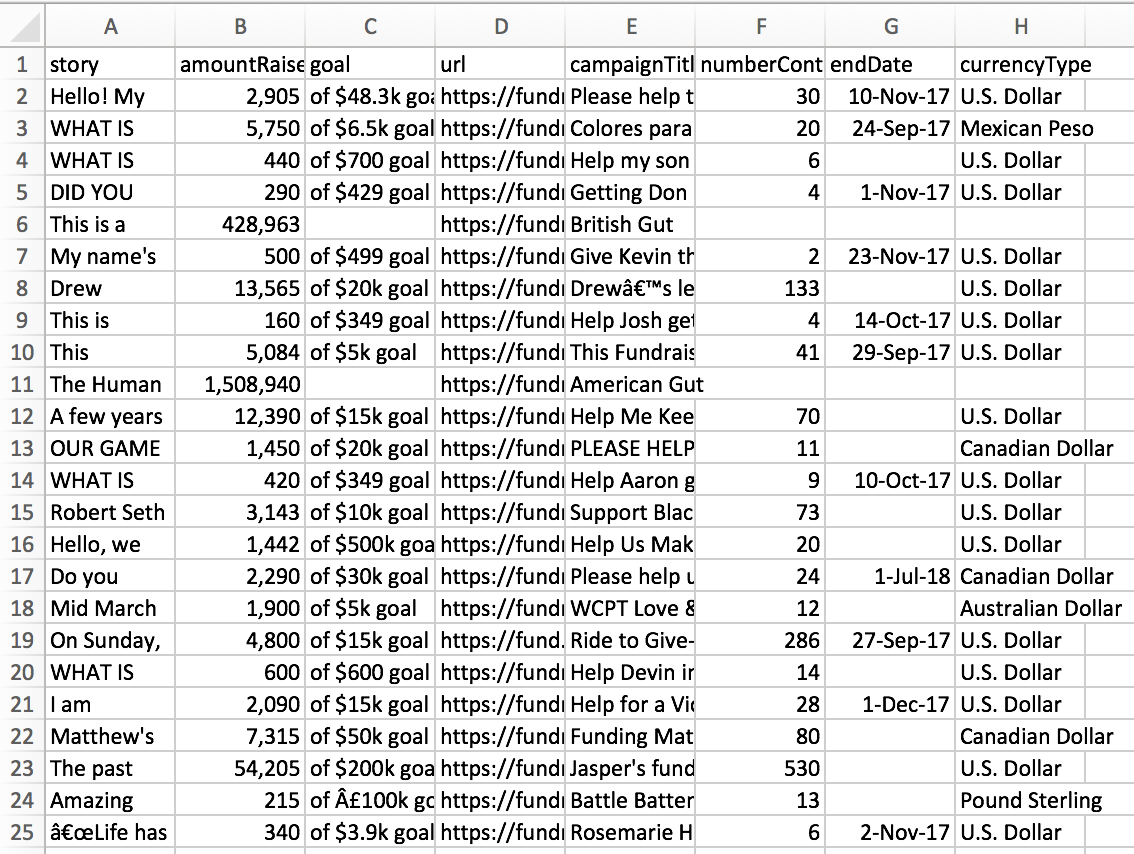
The data should roughly be in this format.
2. If you want to download a larger file (it was made by changing npages = 2 to npages = 450 and adding download_delay = 2), you can download a bigger file with roughly 6000 campaigns scraped by downloading the file from my github. The file is called MiniMorningScrape.csv (it is a large file).
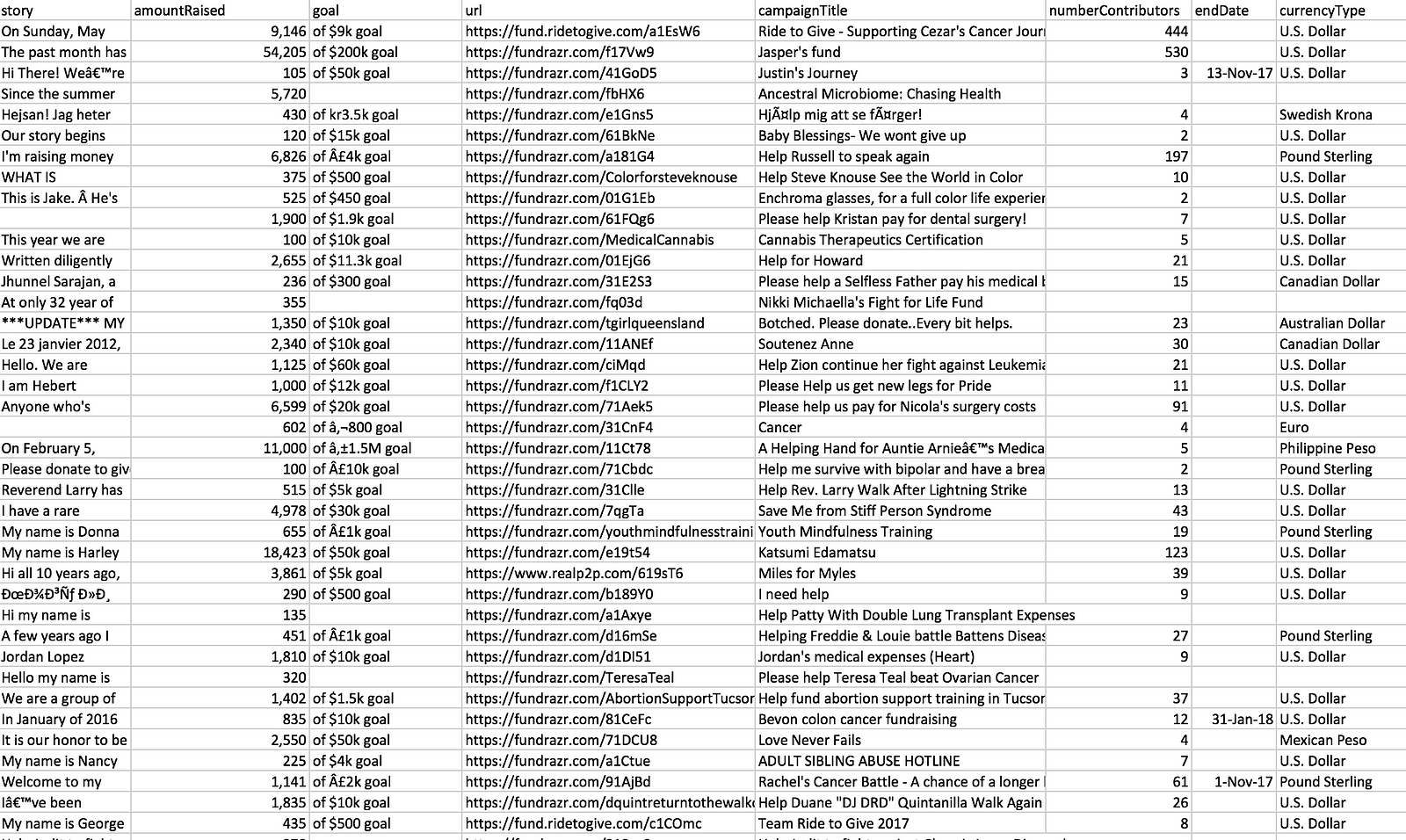
Roughly 6000 Campaigns Scraped
Closing Thoughts
Creating a dataset can be a lot of work and is often an overlooked part of learning data science. One thing we didn’t go over is that while we scraped a lot of data, we still haven’t cleaned the data enough to do analysis. That is for another blog post though. Please let me know if you have any questions either here or on the youtube video page!
This article originally appeared on my medium blog
Can you help me set up a scraping program to extract names and scrores from Leaderboard tables on a Fantasy Sports site?