
The Noob's Prelude to Hadoop: Part 1 - What is "Hadoop"???

The Road Ahead: What This Series Will Cover

Any blog on Hadoop needs at least a brief introduction to the Hadoop platform. However, my exceedingly great early middle-aged wisdom has guided me to examine this platform from a broad perspective with some thoroughness. There is a growing root system of misinformation taking hold out on the World Wide Web. While Hadoop is not the sole elixir for every data related problem that some people (and vendors) would have you believe, it is by no means a one-trick pony, either. There is also a mysterious fog of confusion hanging over the collective mind of the Internet regarding which technologies are part of and related to Hadoop. I am, therefore, taking the time to direct a beam of sunlight into the fog to dispell these myths and illumine you all with an essential awareness of the technologies that exist, how each of them relates to Hadoop, and the specific purpose each technology serves.
This four-part series will clarify what Hadoop is, when you should and should NOT use it, and the fundamental techniques for grokking Hadoop development in a large IT organization.
- Part 1: What is "Hadoop"???
In case you somehow failed to read the title, this very blog post is the first part of this series. In hardly any time at all, I will be leading you through the history and motivations that birthed the Hadoop platform into the world. I will also discuss the four technologies make up the nucleus of Hadoop and the purpose each one serves. - Part 2: Touted Virtues and Hidden Vices
We will mountaineer up the magnificent peaks of Hadoop's most notable merits and take in the view of all it has made possible. Then, we'll descend into valleys of its most dismal deficiencies and observe how it becomes an obstacle when applied in the wrong places. - Part 3: The Wider Landscape
We'll take an expedition through some of the principle Hadoop-related technologies. I will group them into eight main categories and compare the tools and frameworks that are categorized together against each other. - Part 4: Herding the Horde
All of what we have learned up to this point in the series will be brought together to examine how the characteristics of the broader ecosystem of Hadoop-related tools can make it wild and unwieldy in a large IT organization. I will present a few suggestions on organizational structure and development strategies to help you tame the horde within a multi-team environment.
When I was Your Age: A Brief History of the Motivations Behind Hadoop

At the turn of the millennium, the announcement that Google was the largest search engine in the world crowned it king of the hill in Silicon Valley[1]. As its first sovereign act, Google bestowed upon the world two academic papers, "The Google File System" and "MapReduce: Simplified Data Processing on Large Clusters", which contain the secret sauce for how they managed to so efficiently store and index more of the Web than anybody else[2].
Of course, you could imagine, this event was all the rage in the tech community. It wasn't long before a newly established project to create a scalable and extendable web crawler, called Apache Nutch, picked up those papers and used them to create their own filesystem and data processing framework for analyzing boundless quantities of web documents[3][4]. This filesystem and data processing framework became the independent project named "Hadoop" in 2006 when the engineers behind Nutch decided to name it after the stuffed, yellow elephant belonging to the son of then Yahoo! employee, Doug Cutting[5].
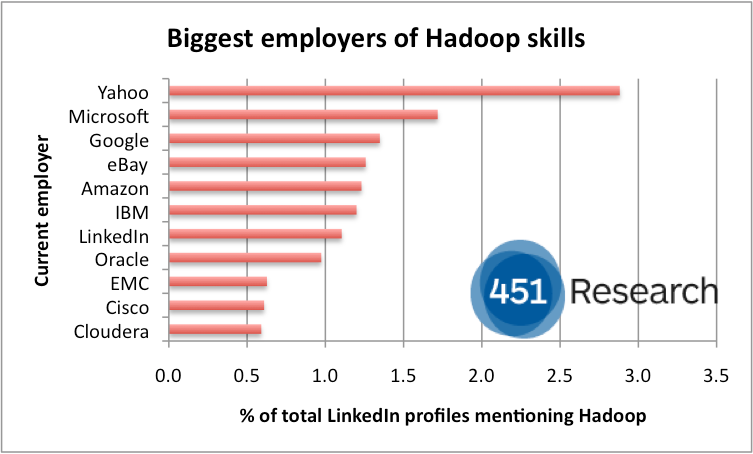
Hadoop has been a highly collaborative project from the start. Not only Yahoo! and Google, but also Oracle, Facebook, and academics like Mike Cafarella have given their sweat, blood, and tears to the project since its inception[5]. The above graphic from 2012 illustrates how quickly the Hadoop project amassed a following. Almost all of these companies made significant contributions to the Hadoop code base by 2011[6]. It's noteworthy that most of these companies would share a similar problem to the one Google was trying to solve in becoming the Master of All Search Engines: archiving and indexing massive amounts of web data.
Due to its great number of participats, many related side-projects have spawned-off the Hadoop Core. Each new twist to the problem of big data has resulted in a new programming framework or cluster management tool. The collective contributions from a growing number of companies, academics, and enthusiasts have created the increasingly expanding Hadoop ecosystem that we have, today[6][7].
What's Part of the Core: Hadoop's Four Central Technologies
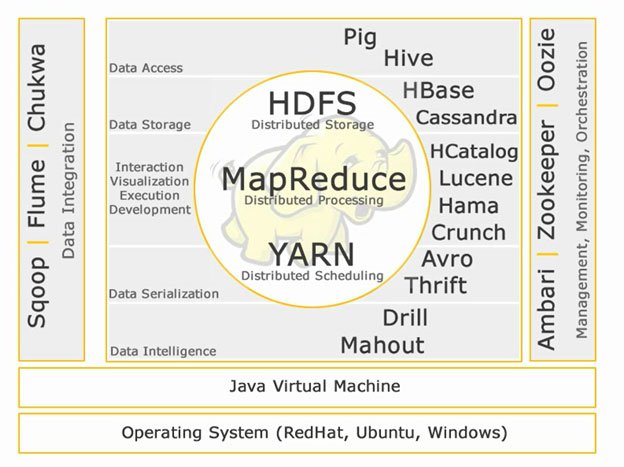
No matter what anyone has told you or what you have read, Hadoop, itself, is made up of only the original three technologies created from the Google research papers: HDFS, MapReduce, and Hadoop Common; and YARN, which came a bit later due to the need for a cluster resource negotiator[6]. Many other projects exist that relate to Hadoop and integrate with one or more of its "core four", but DO NOT BE FOOLED; the projects getting the most attention , in general, do NOT replace Hadoop (see this Question on Apache Spark as an example of the widespread misunderstandings going on). The ecosystem may change and morph, but it will not "get replaced" or "go away" anytime soon.

The larger Hadoop world is a little ambiguous; it can be a bit difficult to determine which technologies are part of the Hadoop ecosystem and which are separate from it. The way I determine whether a technology could be considered related to Hadoop is whether it's created to integrate or interface directly with one of Hadoop's core four or if it organically grew out of the efforts of the Hadoop community such that it's provided by a Hadoop vendor.
An example of a project considered to be part of the Hadoop ecosystem is Apache Spark. It's part of the larger Hadoop world because it was first designed with the intent to interface with HDFS and YARN, even though you don't have to use either one with Spark. It's also not necessary for a Hadoop technology to integrate with all of the four core Hadoop projects. For instance, Spark isn't typically integrated with MapReduce since it's capable of replacing MapReduce as an alternative data processing framework. Apache Spark is a result of the Hadoop ecosystem growing and evolving over time to meet the changing and growing needs of IT organizations with Big Data.
High Performance Computing Cluster (HPCC) is an example of a technology that is not part of the wider Hadoop ecosystem. HPCC was designed to be a direct competitor to Hadoop and claims several advantages over it[8]. Unlike the other Hadoop-related projects, HPCC aims to be an alternative Big Data platform, and that sets it apart from Hadoop.
If you are ever confused about whether a tool or framework is part of the larger Hadoop ecosystem, a good thing to do is check out the websites of Hadoop vendors such as Cloudera, Hortonworks, and MapR to see if any of them include the technology in their platform or are invested in it in some way (such as funding the project or contributing code to it).
We'll explore more Hadoop technologies in "Part 3: The Wider Landscape". For now, let's take a more detailed look at each of the core four.
HDFS
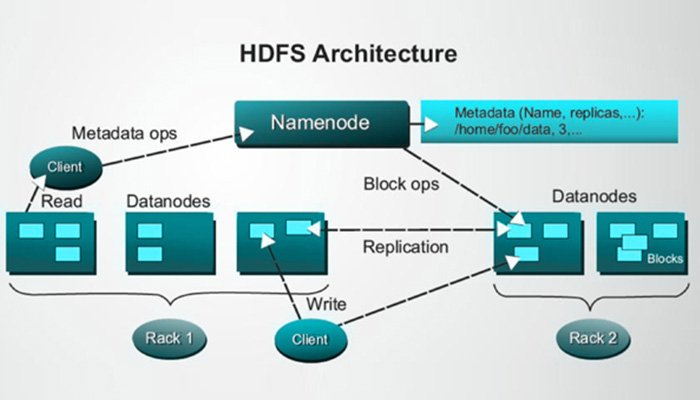
HDFS stands for "Hadoop Distributed File System". If I were forced to pick the essential component of Hadoop, this is it. Most of the tools and frameworks surrounding Hadoop are Hadoop-related because they interact with or manage HDFS in some way. HDFS abstracts all of the storage space on the entire cluster of servers Hadoop is installed on and represents it as a single file system. Its most significant advantages are its ability to speed up massive data imports and exports by spreading the disk IO over the entire cluster's disk array, and the way it redundantly stores the data across multiple nodes to provide resiliency against failures. HDFS is optimized for the storage and batch-processing of files which are each at least as large as several gigabytes, if not terabytes.
The basic way HDFS works is that it is made up of 3 main components: Clients, Namenodes, and Datanodes. The clients are what's used by the user to tell HDFS what to do (mostly read or write operations). The Datanodes are what actually house the data stored on HDFS. There are typically very many Datanodes since HDFS is designed to store massive volumes of data in a replicated, redundant manner. The Namenodes hold the references to and metadata about the data on the Datanodes.
Warning
There is only ever one active Namenode at any given time, but it's a common and most highly advised practice to have at least one or two backup Namenodes ready to go in case the primary one goes down. Since the Namenode holds the references to the data on the Datanodes, if it fails, you lose all of its references to the data. Without a backup, there's no way to recover the data on the Datanodes.
In Part 2, we will cover in more detail the advantages and disadvantages of this design. If you wish to dig into the details of how HDFS works and what it's architecture is like, the official documentation on HDFS's architecture is the best place to start.
MapReduce
MapReduce is a low-level Java programming framework for writing services and apps that process and perform analytics on data in HDFS. MapReduce may also be used to write jobs that import and export data into and out of HDFS. What makes this processing framework special from others is that it will intelligently spread your computations over the entire cluster to take maximum advantage of the available resources across all of the available servers. The MapReduce framework also works with HDFS to try and move the computations developers write in it to the data each requires. This is done because it is assumed that, since HDFS is optimized for storing insane amounts of data, it would be less expensive to move the computation to the data than to move the data to the computation.
At a high-level, MapReduce is made up of 4 processing stages which are always performed in order.
- Splitting : Split the data and distribute it across the Datanodes in the cluster.
- Mapping : Perform a computation over the data on each Datanode that doesn't require sending the data over the network to be shared with anoher Datanode. Most of the time, this computation is something that only works on each record of data in isolation, but you can also perform calculations that aggregate the data per Datanode in some way. These sorts of aggregations are normally done as a preprocessing step to improve performance by giving the Reducers in the last step less work to do.
- Shuffling : Group the data so that each node contains all of the data it needs to compute the final results. This often requires moving the data over the network to make sure each reducer has the entire dataset that it needs to perform its aggregation.
- Reducing : Reduce the data on each node into the final result.
The Split and Shuffle stages often use a baked-in default implementation provided by the core MapReduce Java libraries, but a custom algorithm can be provided by the developer, as well. The Map and Reduce steps, however, are always written by a software developer (most often in Java).
Example :
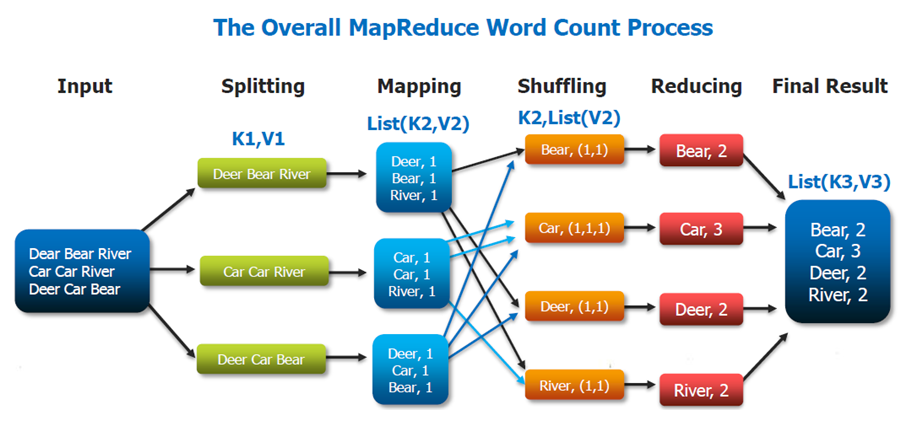
The graphic portrays an example of the Word Count algorithm in MapReduce. This algorithm takes in a document with written text in it and computes how many times each word in the document occurs. The way this works in the MapReduce steps is as follows:
- Splitting : Randomly partition the dataset to send a roughly equal amount of data to each Datanode in the cluster.
- Mapping : Transform the document into a multidict where the keys are the multiset of each word in the document and the values are the integer 1 for every key.
- Shuffling : Send the data over the network such that all instances of the same key reside on the same Datanode. Also, perform a partial aggregation of that data such that each key is unique (make the keys a set) and the values are a list of 1s whose length is equal to the number of times the key occurred in the original document.
- Reducing : Reduce the values from a list of 1s to a single value equal to the sum of all the 1s in that list for each key and output the results.
It's worth noting the MapReduce framework is actually an old and very common design pattern used in "function programming" (FP). In big data distributed computing, FP techniques tend to pop-up regularly due to the immutable nature of FP and the difficulty in managing shared, mutable state in highly distributed and concurrent environments (like Hadoop). As a result, I will cover FP topics fairly frequently in this blog in the future.
If you want to dig deeper into MapReduce and how it works, once again, I refer you to the official documentation.
YARN
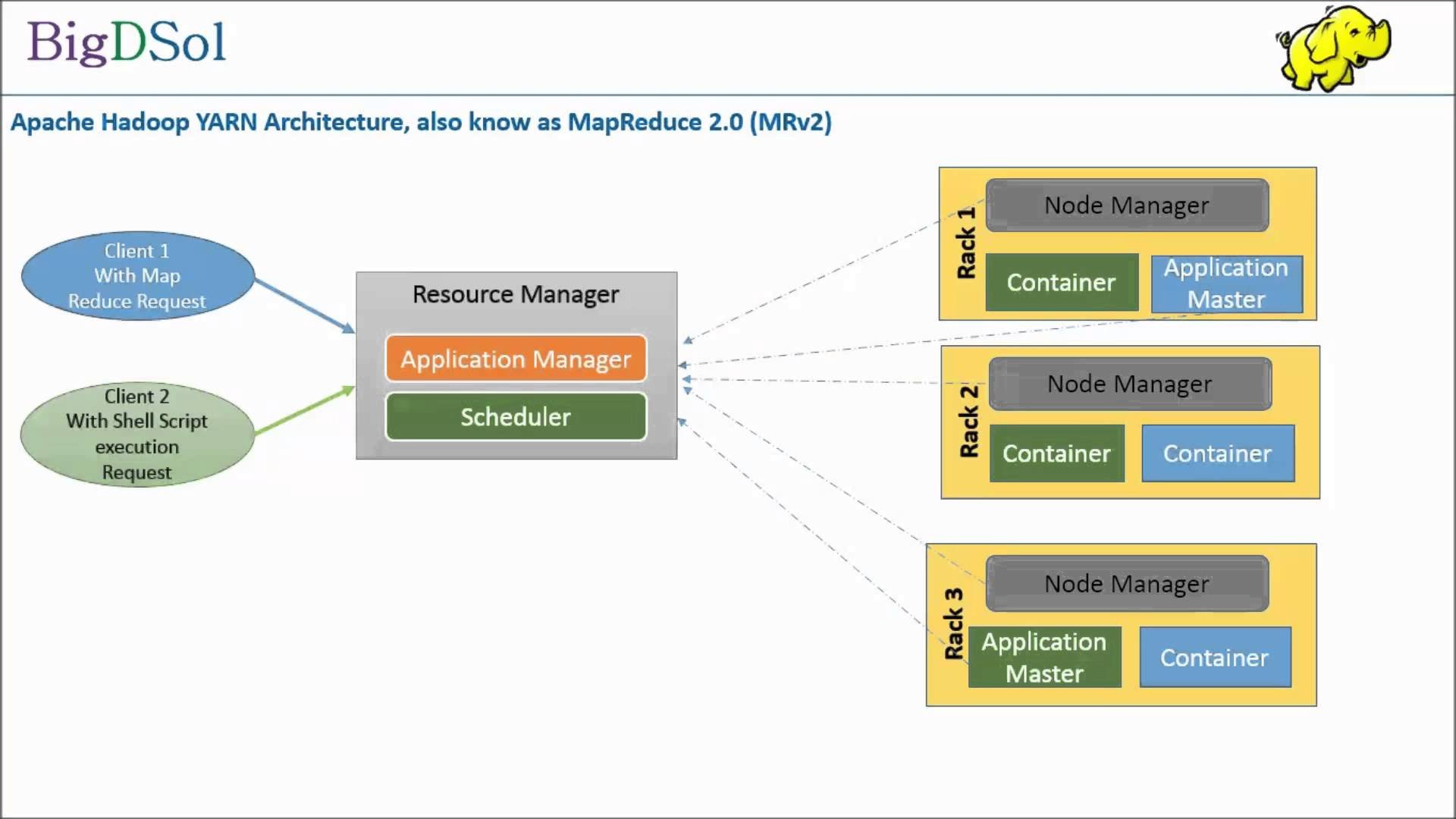
YARN stands for "Yet Another Resource Negotiator". Its main functionality is to provide scalable cluster-wide dynamic resource management, job scheduling, and monitoring. YARN is made up of three daemons which do pretty much what you'd expect from the name: ResourceManager, NodeManager, and ApplicationMaster.
Specifically, the ResourceManager allocates the high-level system resources across Hadoop to each application running on the cluster. NodeManagers monitor each piece of work running as part of an application (refered to as a "container" or a "task") on a particular node and report back to the ResourceManager on their observations regarding the resource usage of each task. The ApplicationMaster requests resources from the ResourceManager and assists the NodeManagers in running and monitoring the tasks sent to each node.
If you are still curious about the finer details on how these three daemons work together in YARN, the official documentation gives a good overview of the responsibilities for each one.
Hadoop Common
Hadoop Common is often forgotten about because its presence and use is not as obvious. This project is basically where developers throw modules of code that are "common" across two or all of the other three core Hadoop subprojects.
All other tools and frameworks outside of the above four, while they may be Big Data or Hadoop-related projects, they are not part of core Hadoop, itself.
Continue to Part 2: Touted Virtues and Hidden Vices
In the next part of this series, we will explore and compare the aspects of Hadoop's most considerable advantages and disadvantages.
Part 2 is not ready, yet. Please check back in a couple of weeks when I will update this post with a link.