
Building a traffic fine scraper with Python
To see this post in a better format, check my blog.
Motivation
The other day I was remembering that during my visit to Mexico City back in June '17 (for my participation on the first edition of the PythonDay México), a friend of mine hosted me at his house during my time there. The thing is that during my stay we were talking about building something that could be useful, so we decided to scrape a website in which car owners from Mexico City would be able to verify their traffic fines.
The website is the following: http://www.multasdetransito.com.mx/infracciones/df-distrito-federal
As you may have noticed if you opened the site, it contains an input to write down the car plate from which you can search the traffic attached to that plate (if it has any).
My friend told me that only a small group of Mexico City residents knew about that site, so it might be useful to create something in which they can consult this info in an easier way.
After this, I was like: "Dude, today I held a workshop on how to build a TwitterBot in 30 minutes for the PythonDay, what if we build a TwitterBot that inputs the plate in the site and then scrapes the info from it automatically?". He said yes. With this, we built MultaBot a TwitterBot that used to read a car plate and scrape for its traffic fines.
We started with this project as a private project, but the other day I was invited by the Division of Law, Politics and Government of my university to give a tech talk about how automation can be useful for future jobs not for only people in tech industry, but also for politicians and lawyers. When I remembered about this, I thought that it would be a nice example, so I wanted to improve on its base and ended with this example script that now I want to share with you.
Experimentation
I'll explain the whole code, so you'll understand what's happening every tep of the way. To begin, I'll import Selenium and the Python data pretty printer:
1 from selenium import webdriver
2 from pprint import pprint
Selenium will allow us to automate the control of a web browser, so the idea will be to use it to automatically open the website, input the car plate and after the traffic fines are loaded, extract and parse them for the pprint output.
After this, I created a function to launch the browser and scrape the info off of the car plate. If verbose is set to True, the function will print the details of each traffic fine:
5 # Browser opener function:
6 def launch_browser(placa, verbose=False):
7 # Browser launch with chromedriver:
8 browser = webdriver.Chrome()
9
10 # Set url and open it on Chrome:
11 url = 'http://www.multasdetransito.com.mx/infracciones/df-distrito-federal'
12 browser.get(url)
13
14 # Search plate:
15 multas = busca_placa_df(browser, placa, verbose)
16
17 # Close browser:
18 browser.quit()
19 return multas
Inside the function I set the url to be scraped, then I called function named busca_placa_df (which means search_plate_df, df stands for Federal District in Spanish) and then I closed and quit the opened browser for this search.
Then, I built the main function that inputs data and then scrapes the traffic fines:
22 # Plate finder function:
23 def busca_placa_df(browser, placa, verbose=False):
24 # Find ID and input test data:
25 browser.find_element_by_id('plate').clear()
26 browser.find_element_by_id('plate').send_keys(placa)
27
28 # Look for button and click it:
29 browser.find_element_by_xpath('//*[@id="request"]/div[2]/div/a').click()
30
31 # Search result and return it:
32 resultado = browser.find_element_by_id("secciones")
33 if resultado.text == "INFRACCIONES":
34 resultado = "¡No tienes adeudos!"
35 else:
36 resultado = resultado.text
37
38 # Search infraction tables:
39 if verbose:
40 infractions = browser.find_elements_by_id("tablaDatos")
41 if len(infractions):
42 for index, infraction in enumerate(infractions):
43 raw_data = infraction.text.split('\n')
44 folio, fecha = raw_data[1].split(' ')[0:2]
45 situation = ' '.join(raw_data[1].split(' ')[2:])
46 motive = ' '.join(raw_data[2].split(' ')[1:])
47 items = raw_data[3] + ' , '
48 its = [item.split(' ')[-1] for item in items.split(', ')]
49 art, fac, par, inc = its[:4]
50 sanc = raw_data[4]
51
52 data_dict = {
53 'Folio': folio,
54 'Fecha de Infracción': fecha,
55 'Situación': situation,
56 'Motivo': motive,
57 'Fundamento': {
58 'Artículo': art,
59 'Facción': fac,
60 'Párrafo': par,
61 'Inciso': inc,
62 },
63 'Sanción': sanc
64 }
65 print("Infracción {}:".format(index + 1))
66 pprint(data_dict)
67 print()
68
69 return resultado
As you see, in lines 24-26 I clear the data in the input field with id=plate from the HTML source, then input the car plate that I want to look for, and after this I look for the button by its XPath and click it (lines 28-29).
I now want to know the results for the search, for this I look for the element with id=secciones in the HTML of the response (lines 31-32) and first verify if it has any debts by looking if the resulting text is only "INFRACCIONES", if so I returned a message saying t has no debts (lines 33-34). In the other case, in lines 35-36 I save the result with the text it contains (which specifies the number of traffic fines for the plate).
If the verbose flag is turned on, then the scraper will get all the info of each traffic fine (lines 38-40). For this, it will look for the element with id=tablaDatos in the HTML, which contains all the info of each traffic fine and if it is not empty (line 41) it will iterate for each traffic fine and then extract all the info them (lines 42-50). I now build a dict with the response to serve it in a nice way using pprint (lines 52-67) and return the result (line 69).
To test the script I just called the function launch_browser with a demo car plate (that coincidently has 2 traffic fines) and print out the results (lines 72-74):
72 if __name__ == '__main__':
73 multas = launch_browser('MKJ3940', True)
74 print(multas)
If you run this in a script, you'd get an output like this one (note that it prints the 2 traffic fines I mentioned 😝):
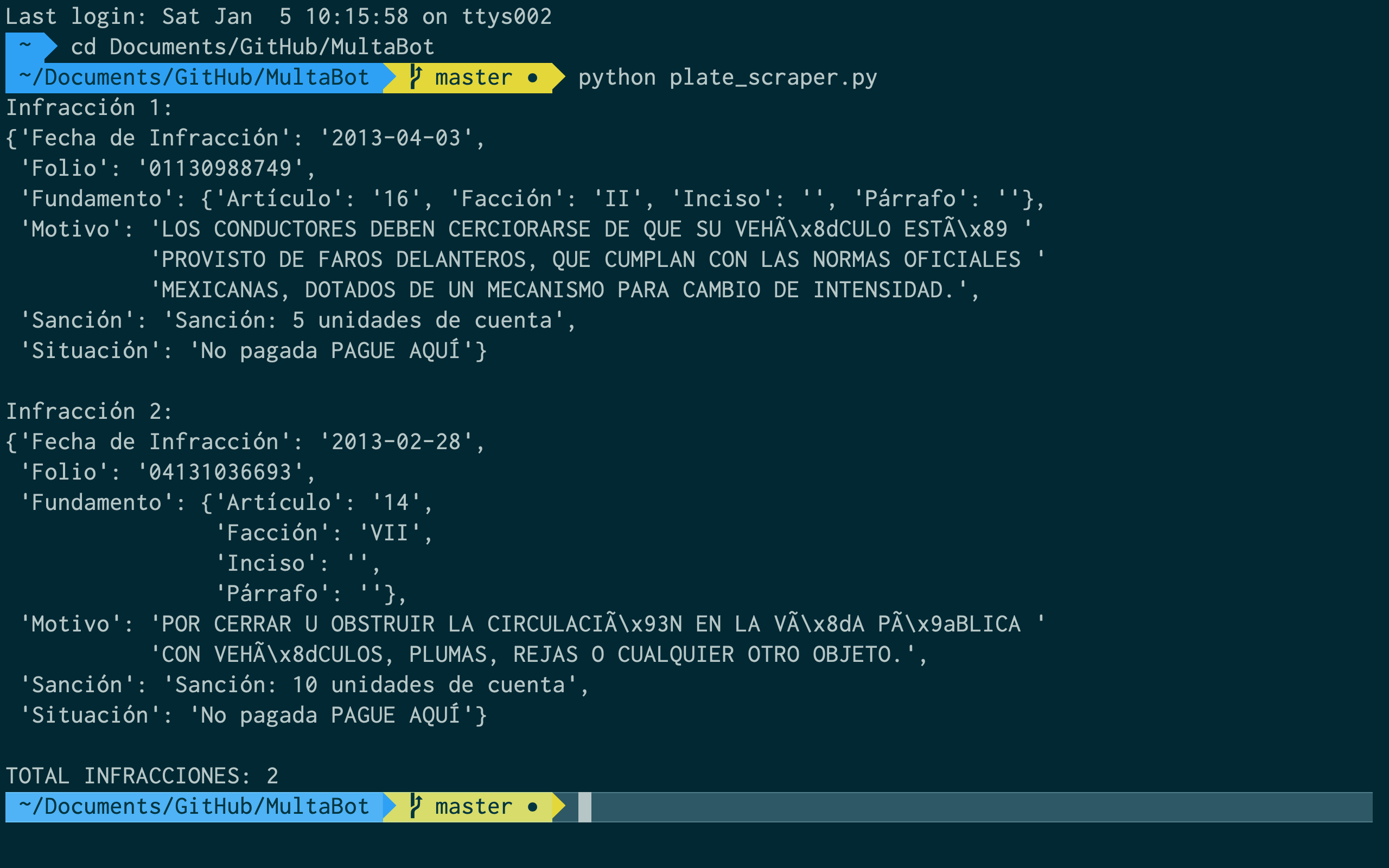
Conclusion
At the beginning, what we thought would be a project just for fun to work together that night –like a mini hackathon– ended up being a useful project that could be helpful for citizens in Mexico City.
As you have seen, Python has tools that help to automate some things in very cool ways. I mean, if you run the script as it is provided, you should see a browser window to open automatically, then the text gets written alone in the input field and the results are shown by their own. Isn't this really awesome?
Please let me know what you build with Selenium and Python in the comments! 💻🐍🤙🏼
Hi! I am conducting a research on the key success factors of #freelancers in India, Philippines and USA. If you are a #freelancer from any of these countries, please answer the survey below and 20 respondents will get $5 USD each! https://www.surveymonkey.com/r/BBBTPZD #freelance Thank you!
I created a function to launch the browser and scrape the info off of the car plate. If verbose is set to True, the function will print the details of each traffic fine:
5 # Browser opener function:
6 def launch_browser(placa, verbose=False):
7 # Browser launch with chromedriver:
8 browser = webdriver.Chrome()
9
10 # Set url and open it on Chrome:
11 url = ‘http://www.multasdetransito.com.mx/infracciones/df-distrito-federal’
12 browser.get(url)
13
14 # Search plate:
15 multas = busca_placa_df(browser, placa, verbose)
16
17 # Close browser:
18 browser.quit()
19 return multas
Inside the function I set the url to be scraped, then I called function named busca_placa_df (which means search_plate_df, df stands for Federal District in Spanish) and then I closed and quit the opened browser for this search.
Then, I built the main function that inputs data and then scrapes the traffic fines:
22 # Plate finder function:
23 def busca_placa_df(browser, placa, verbose=False):
24 # Find ID and input test data:
25 browser.find_element_by_id(‘plate’).clear()
26 browser.find_element_by_id(‘plate’).send_keys(placa)
27
28 # Look for button and click it:
29 browser.find_element_by_xpath(’//*[@id=“request”]/div[2]/div/a’).click()
30
31 # Search result and return it:
32 resultado = browser.find_element_by_id(“secciones”)
33 if resultado.text == “INFRACCIONES”:
34 resultado = “¡No tienes adeudos!”
35 else:
36 resultado = resultado.text
37
38 # Search infraction tables:
39 if verbose:
40 infractions = browser.find_elements_by_id(“tablaDatos”)
41 if len(infractions):
42 for index, infraction in enumerate(infractions):
43 raw_data = infraction.text.split(’\n’)
44 folio, fecha = raw_data[1].split(’ ')[0:2]
45 situation = ’ ‘.join(raw_data[1].split(’ ')[2:])
46 motive = ’ ‘.join(raw_data[2].split(’ ‘)[1:])
47 items = raw_data[3] + ’ , ’
48 its = [item.split(’ ‘)[-1] for item in items.split(’, ')]
49 art, fac, par, inc = its[:4]
50 sanc = raw_data[4]
51
52 data_dict = {
53 ‘Folio’: folio,
54 ‘Fecha de Infracción’: fecha,
55 ‘Situación’: situation,
56 ‘Motivo’: motive,
57 ‘Fundamento’: {
58 ‘Artículo’: art,
59 ‘Facción’: fac,
60 ‘Párrafo’: par,
61 ‘Inciso’: inc,
62 },
63 ‘Sanción’: sanc
64 }
65 print(“Infracción {}:”.format(index + 1))
66 pprint(data_dict)
67 print()
68
69 return resultado
see : https://pnrstatus.vip/ , https://textnow.vip/ , https://downloader.vip/vpn/