
Greedy Local Optima, not a Global Optima Make
Introduction
Quite regularly, decomposing software into solvable chunks results in a series of combined solutions which in themselves seem sensible and even optimal, but at the same time, don't systemically work as well as they should when combined. Those times, stepping away from the code is one of the best ways to get a more holistic view of the purpose of your code and it's performance.
A classic example I often showcase is a problem I came across in 2000. As a senior developers and software architect for a large UK insurer in the City of London, I was tasked with finding a solution to improve the performance of a bespoke service.
The Problem
The service needed to handle multiple autonomous agents (read, Windows services), each of which was running varied workloads on varying hardware servers! The latter was a constraint introduced by the company.
The combination of not being able to obtain adequate server hardware and the temporary nature of the system, meant my boss required me to work some magic and get the system to work on throwaway hardware, without installing Linux.
After scribbling down a lot of math, the solution I proposed was an adaptive load balancer. It simply adapted to the load that came in by keeping a tally of connections and adapting to the mean of the latency on each of the servers we were given. It would also judge each agent's performance and so would route traffic to the most appropriate node given it's average performance over it's lifetime and the number of connections it currently had. It was called MAALBA (Mean Average Adaptive Load Balancing Algorithm) - So very geek! I could have done with a better name.
As I started building this thing, the biggest problem didn't come from the adaptive service itself, it came from the humble average calculation! One of the most basic mathematical tools you could get! One baked into pretty much, every language library.
O(n) Algorithm & finite space
Let's revisit the humble average.
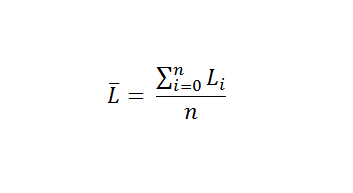
Complexity wise, calculating averages is an O(n) operation. As the list if the numbers to add increases, the computation rrequires one more addition. It grows as linearly as the list does. For smaller numbers, this is fine. However, as the numbers get bigger, this starts to slow down the algorithm linearly too.
This same problem leads to another issue. Adding positive numbers approaches infinity as the size of the list approaches infinity. Yet, computers can't add up to infinity. Numbers overflow long before then.
Rethinking the Problem: What's the ultimate goal?
In order to solve these two problems I had to rethink how averages were calculated and realised we'd have to do away with the default library, given we'd be recalculating the slowing average performance every single time a request was made. I needed to find a way to improve the complexity on the average calculation.
The first step looked at finding an algorithm that approached O(1). This turned out to be quite elegant. It meant restructuring the average against the previous average, together with a coefficient and constant addition.
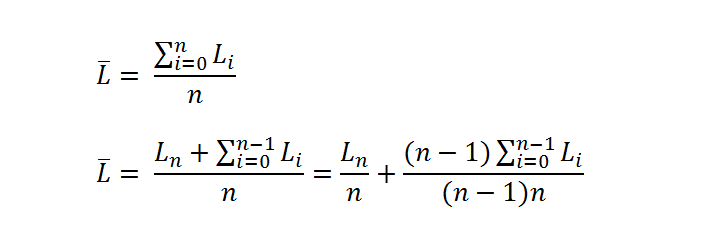
Which means
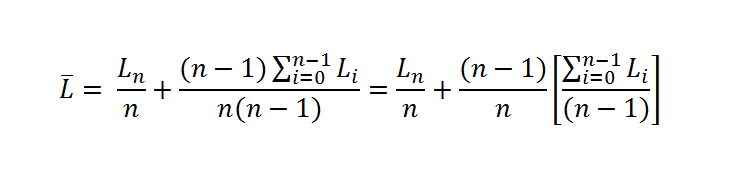
And the final result starts to form a new equation.
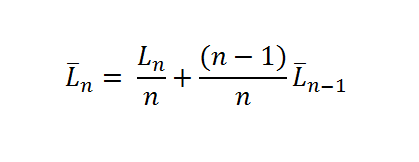

Performance Benchmark
OK, we've talked the talk. Best get coding!
To rewrite it now and as a .NET guy, it's C# time!
As always, we start with our tests (TDD).
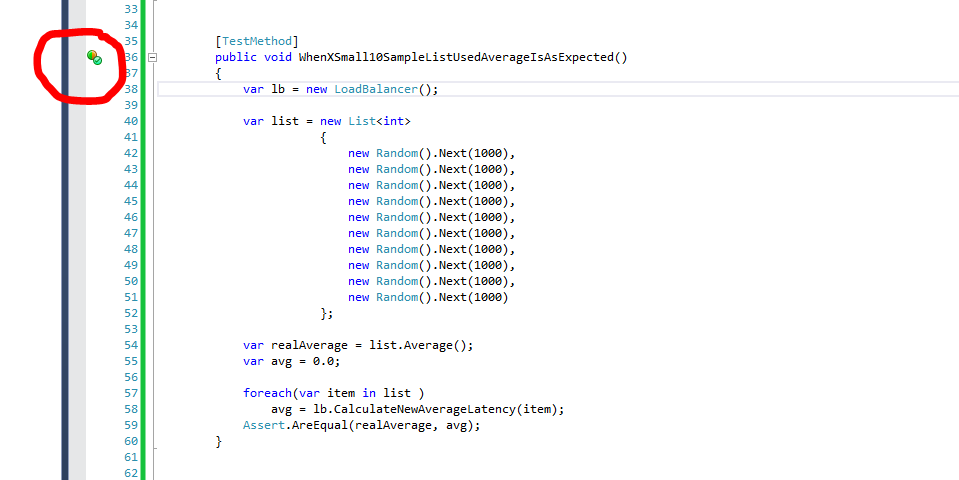
The it's time to build the code to make it pass.
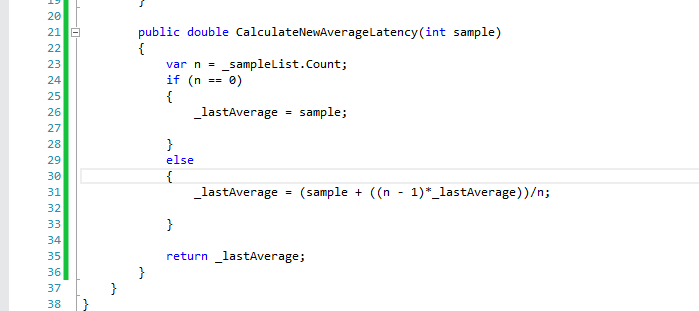
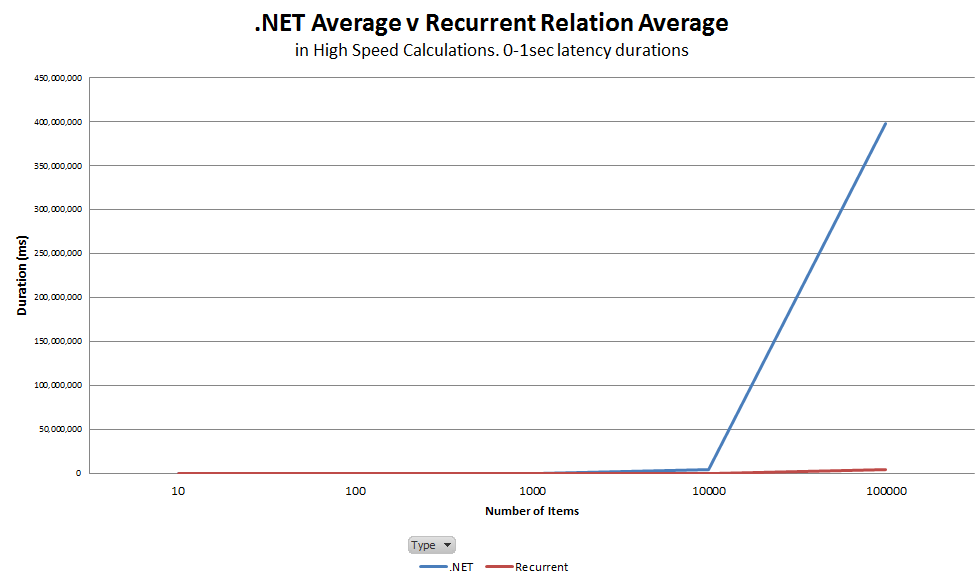
Using this same test suite, we can run this for various sizes of input data, allowing us to plot a graph on alogarithmic axis.

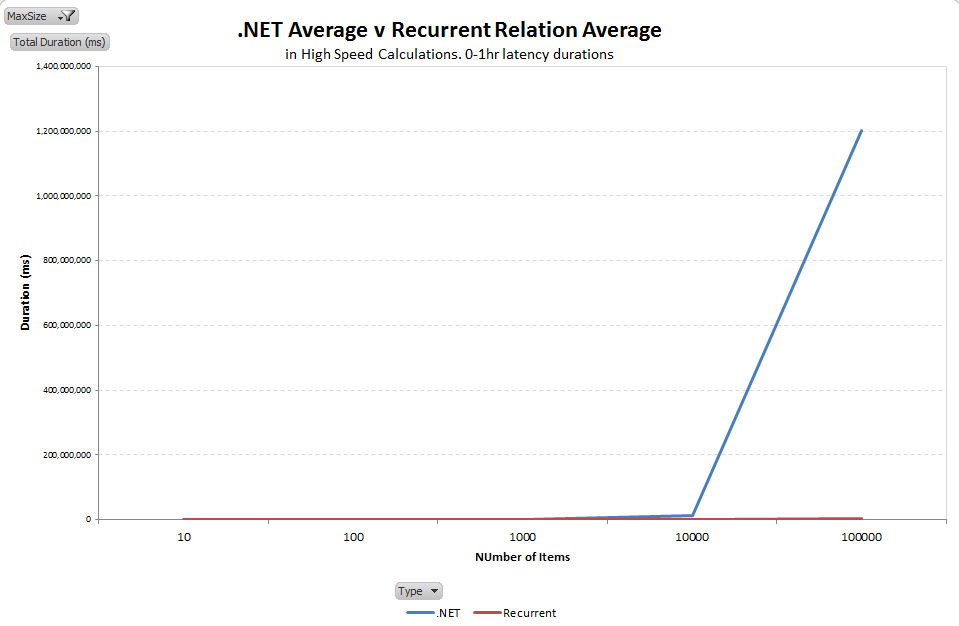
Conclusion
As the system hit 100,000 items in the list, the standard average calculation failed to perform to even 1% of the speed of the recurrent algorithm.
As you can see from the above results, the standard, vanilla .NET average calculations in the Math class performed really poorly compared to the recurrent version of the code for this type of problem. So you could be forgiven for thinking I am about to tell you to ditch the .NET version.
Far from it! The only reason this worked is because of the systemic need to accumulate the latency. It converged to a value, in this case the average, and the prior 'knowledge' the system had, wasn't changing. If we needed to go back and change the numbers of the historic data, we would be stuck with a system which could only use the standard average calculation and nothing more! Since we'd have to reprocess the samples and the history each time.
This just goes to show that contextual awareness of an algorithm is a really importance factor in the design of high performance systems. Unfortunately, it's one of the things you can't refactor to alone. Refactoring may given you the ability to pick out the old average calculation method to then replace with this, but not develop the algorithm for a new one such as this, especially from scratch. Anyone beating on anyone else for 'analysis paralysis' should hopefully be hanging their heads in shame at this point because sometimes, it's necessary!
This article first appeared in my blog. It's been rewritten for greater clarity on Codementor.io.