
Simplifying your microservices architecture with Kafka and KafkaStreams
If you live in a world of microservices, you are probably aiming to build really small services that have their own database which no other service can peek into, and that publishes events into some messaging infrastructure.
This gives you a nice loosely coupled architecture where services can come and go, be rewritten or retired, and new functionality can be build without having to touch the working services.
Apache Kafka is often chosen as the messaging infrastructure for microservices, due to its unique scalability, performance and durability characteristics. It supports both queue and topic semantics and clients are able to replay old messages if they want to.
Last week we started to build one such microservice, whose job was to:
Send a weekly email to clients holding trading positions in any US stock.
Plain old solution
This is the architecture that we would have traditionally use for such a microservice:
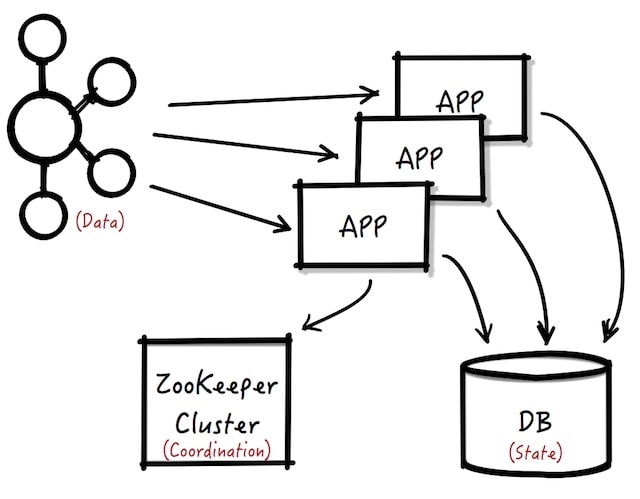
- Kafka: the source of the event data.
- Database: to track the US open positions for each client. We will need to keep it updated as we consume new messages from Kafka.
- Zookeeper’s leader election or Quartz Clustering, so only one of the instances of the service sends the email.
This is fairly complicated and will require lots of code.
Kafka Streams’ solution
Kafka Streams is a new open source library, part of the Apache Kafka project, that promises to make stream processing simple without losing the power and scalability of other stream processing systems like Storm or Spark Streaming
The major selling points for me are:
- Scalable, using the same partition-based model as Kafka.
- Real time, optional micro-batching.
- Stateful stream processing.
- It is a library, not a framework.
Kafka Streams don’t need any new infrastructure, depending only on the Kafka cluster (and the Kafka’s Zookeeper cluster until KIP-90 is done).
Apart from a nice functional API similar to Java 8 streams, Kafka Streams introduces the concept of a KTable. Let’s try to explain what a KTable given the requirements we have.
Each time a new trading position is opened or updated, the order booking system sends to a Kafka compacted topic the full state of that position, using the position id as the key. When an position is closed, it will send a null to delete it from Kafka.
As we are using a compacted topic, Kafka will just remember the latest value sent for each key, which means that we can reconstruct the original table by just replaying all the messages stored in Kafka.
So conceptually we can think about that Kafka compacted topic as a table like:
| PositionId (Key) | Client | Ticker | Amount | Exchange |
|---|---|---|---|---|
| 1 | client1 | AAPL | 100 | NASDAQ |
| 2 | client1 | VOD | 5 | LON |
| 3 | client1 | FB | 33 | NASDAQ |
| 4 | client2 | AAPL | 25 | NASDAQ |
| 5 | client3 | VOD | 33 | LON |
For our requirements, we need to basically execute the following SQL query:
select distinct(client) from open_positions where exchange = 'NASDAQ'
Which using the KTable API from Kafka Streams, looks like:
(->
(.table builder "share-holders" "share-holder-store")
(.filter (k/pred [key position]
(= "NASDAQ" (:exchange position))))
(.groupBy (k/kv-mapper [key position]
(KeyValue/pair (:client position)
#{(:id position)})))
(.reduce (k/reducer [value1 value2]
(set/union value1 value2))
(k/reducer [value1 value2]
(let [result (set/difference value1 value2)]
(when-not (empty? result)
result)))
"us-share-holders"))
This will generate a distributed, fault tolerant, highly scalable KTable that will contain:
| Client (Key) | positions |
|---|---|
| client1 | #{1, 3} |
| client2 | #{4} |
Now that we have this KTable, we just need to query it to get our list of clients:
(with-open [all (.all
(.store kafka-streams
"us-share-holders"
(QueryableStoreTypes/keyValueStore)))]
(mapv
(fn [x] (.key x))
(iterator-seq all)))
And there it is!
If we look at the architecture of this solution, it looks like:
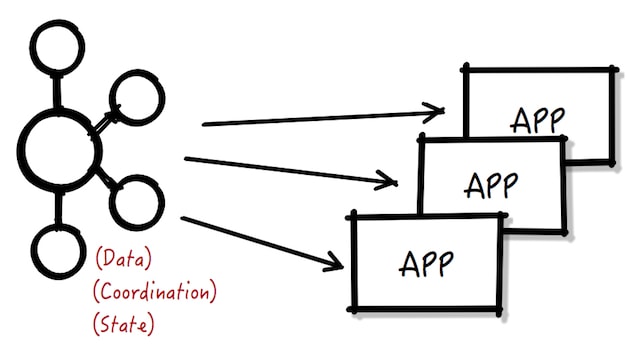
Which is simpler and has less moving parts than the previous one.
Conclusion
For this particular use case, Kafka Streams and KTables really delivers.
First, the code is really simple, way simpler than the traditional solution.
Second, we are avoiding a shared database, so one less component in our architecture, one less thing to maintain, one less thing that can break.
Third, Kafka Streams take care of sharding the work, each instance able to prepare and send the emails for a subset of the clients. This brings scalability, plus it removes the additional coordination component.
Lastly, it is a library, so you can mix it with any other libraries that you like and use whatever tools you usually use for your deployments. It doesn’t require anything special.
Of course, if you look at the SQL statement, you may wonder if the cost of microservices is really worth it, but that is a question for another day.
If this looks interesting, I recommend reading Jay Kreps excellent intro (plus the Confluent blog is excellent) and the very high quality Kafka Streams docs.
You can read about the implementation details, gotchas and find a full working Docker environment in the following blog post.
Or you can read about joins on stateful stream processing using Kafka Streams’ KTables and GlobalKTables.
All in all, Kafka Streams looks very exciting and we will definitely explore it further.