
Java with a Clojure mindset
Video, transcript and slides from the Java2Days and Oredev 2018 talk
In this talk, using a real application as an example, we will learn how to build and design Java applications that follow Clojure’s functional principles using just core Java, without any libraries, lambdas, streams or weird syntax; and we will see what benefits those functional principles can bring.
A teaser first:
Here are the slides in keynote format, ppt format (untested!) and SlideShare (somehow broken!).
And the video:
Feedback and questions welcomed!
Transcript
Lets start with a quizz. Who can tell me what is this?

This is how Clojure looks like the first time that you see it.
And I want to point out 3 important things in this picture.
First, it is very ugly, some people would say that it is even disgusting.
Second, there are a lot of things that make no sense at all. For example, why would you want to keep a bug in your mouth?

Or what the hell is that and what it is doing there?
But last, and most importantly, it is alien. And when we look at that picture, we are looking at it from our human point of view, from our Java perspective.
So maybe we are not being fair, and with enough time,

and the help of the hypotoad, maybe that picture would look like this:

because with understanding, it will come a change on perspective, that will allow us to make a more fair judgement.
And I know what you are thinking, Wonderwoman is not technically an alien and if we are talking about Clojure, the picture is missing
some parenthesis.
But still, if we spend sometime studying these aliens, maybe we will find some superpowers that we can use in our day to day job as Java developers.
Clojure
So what is Clojure? Clojure is a Functional, Hosted, Dynamic and strongly typed, lisp for the JVM.

So what we are going to do in this session is, using a real world application as an example, see how Clojure affected the way that we built, the way we designed this Java application, how Clojure infected our Java code.
To give a little bit more context, when I got involved with this application,

I had already been a Java developer for 12 years, and a Clojure one for 3, so when I got involved I had reached Wikus Stage 2 on my journey, on my transformation, to a full blown alien mind.
The application that we are going to be talking about, is one of this bonus systems that you find in some betting industries.

Those of the kind of “if you put some money in your account, we will give you double that amount for free” or “if you join us now, we will give you a 1000 euros free cash!”.
Now nobody is going to give you any free cash, so if you read the T&C, to be eligible to withdraw that “free” cash, to be able to get that cash and put it in your pocket, you had to first play or bet, a number of times in the system, or do a number of activities.
Also, in our particular case, and I am not sure if this is common, the client had a limited amount of time to place all these bets.
So removing all the marketing fluff, what our application had to do was something like this:
add some amount of money to the client account, if they had sign up for the bonus and they had made loads and loads of bets, within some timeframe.
So from an implementation point of view, what the system had to do is know which bonus where available, which clients had sign up for one of those bonus, and then keep track of the interesting activities of those clients, which in our case would be making a bet and placing a deposit.
Functional vs OO
So lets start with the first of the differences: Functional vs Object Oriented.
Of the many principles, concepts and techniques that are usually associated with FP, I just want to focus on one that, in my personal experience, has made the biggest impact on the way that I design applications. And I think it is specially important because it is easy to translate, to use it most languages.
Pure Functions
This is the concept of pure functions.
Pure functions are pieces of code that for a given input, they are always always always going to return the same result. Always. So same input, same output.
And why are pure functions so important? Pure functions have multiple benefits, but the key one is that pure functions are easier to reason about, because all the code within a pure function just depends on the input parameters. So the context that you need to keep on your head to understand a pure functions is small.
Pure functions are like physic laws,

because you know how a pure functions is going to work and you can rely on it working the same every single time.
And as pure functions are easier to understand, it also means that they are easier to change.
And change is what we, developers, do for a living.
Programmers are constantly in maintenance mode. The Pragmatic Programmer
We very rarely write a new piece of code. Most of the time, we are just making changes on existing systems. Even if you created your project 15 minutes ago, you are already in the business if changing existing code.
Side effects
And when talking about pure functions, we have to talk about its evil twin, side effects.
Side effects is what makes your code hard to understand, because suddenly, to understand a piece of code, it is not enough to look at that code. Now you also need to understand all its dependencies, and all the libraries that are being used, and all the possible states in the database, and all the possible states of the network, and all the possible things that multiple threads could be doing at the same time.
The context that you need to keep in your head is huge.
Once you have side effects,

you are not sure what is going to happen when you make a change.
Well, that was a bit side effect. And this happens to us all the time. You make a small, and what you think is an innocuous change, on one side of your application and then suddenly a completely unrelated feature in the other side breaks without you ever noticing.
So for me, a key insight on functional programming, is that side effects are the enemy.

So functional programming is about fighting and controlling side effects.
There are basically two kinds of side effects:
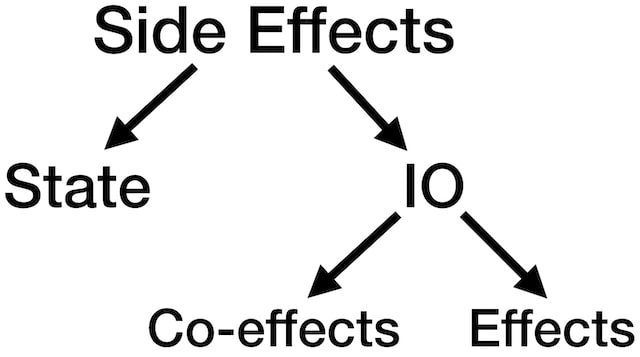
- Those side effects that change the state of your application
- And then we have IO side effects. Of the IO side effects, I want to distinguish the Input side effects, sometimes called co-effects from the output side effects, called simply effects.
State
So let’s start by talking about how we can fight state.
In the case of the bonus system, our application has to keep track of the state of each client and its progress on the bonus campaign.
To do that you can image that the application kept a map, with the client id as the key and some kind of ClientBonus object as the value. This ClientBonus object itself could have maybe Client object and a bonus object. Also, it will also have to keep track of the deposits made, so it could have a DepositList, which will contain a bunch of Deposit objects, and each of these deposits objects could contain even more objects. In a similar way, it would need to keep track of the bets done by the client.
So these would be our object graph, and we would have one of these graphs per client.
Now when it came to state management, I would traditionally made each object responsible for its own state change. So the Map would get its own little machinery, its own little piece of code to manage its internal state and to make sure that if several threads try to manipulate or read the map, they will see a consistent state.

In a similar way, the ClientBonus object would also be responsible to manipulate its own state internal state and to provide a consistent view of it, and the same for each and every object.
Now, from a complexity point of view, what does it mean that each object gets its own machinery to control its state? Each of those little machines are possible side effects that you have to take into account whenever you make a change to your code. You not only you have to think about the business logic that you have to write, you also have to thinking about any timing issues due to concurrent access to the objects.
So the code is mixing in the same place business rules and concurrency rules.
So what Clojure teach us is that, to simplify this, what you want to do is separate application logic, your business logic, from any state management, so you don’t need to think about both at the same time.
So how we do this? First by making everything immutable, everything is a value, even that map holding all of our ClientBonus objects. Now that everything is immutable, when writing your application logic, you do not need to think about timing, you do not care about what other threads are doing at the same time, because none of them can change to your object graph. So this frees your mind, this makes writing your application logic a lot simpler.
For the state management part, Clojure comes with a construct or a class, called Atom, which is basically the same as a Java AtomicReference, but with a little bit more functionality.
atom =~ j.u.c.a.AtomicReference
Lets see how an atom works.
An atom holds a reference to the whole immutable value, to the whole state, and your job as a developer is to write a function, that takes the current state as a parameter, and it produces the new state, and the atom machinery will make sure that the transition from one state to the next is done in an atomic way.
To understand it better, lets see what happens if two threads try to modify that state at the same time.
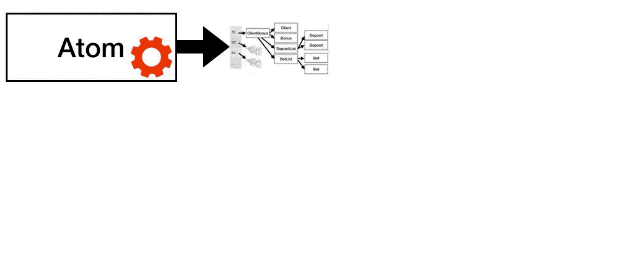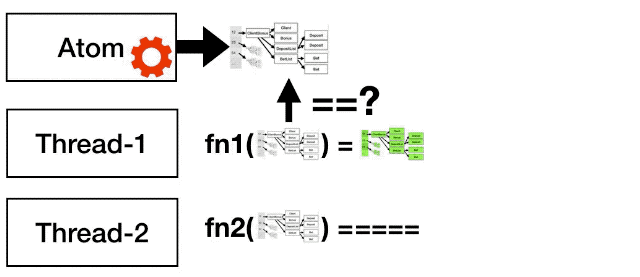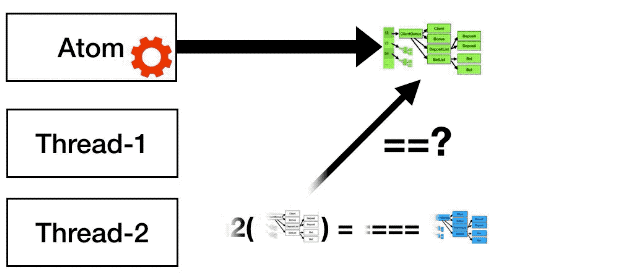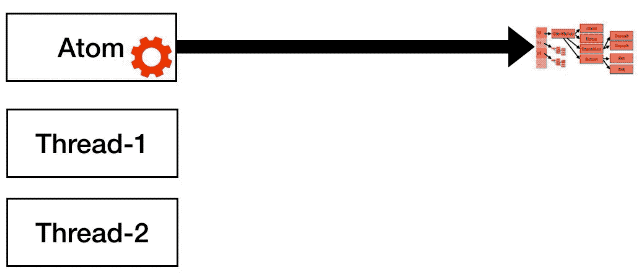
Both threads will get the initial state and will start calculating the next state. Lets say that thread-1 finishes before thread-2. At this point thread-1 tries to change the state of the atom, to the new green value. To do that it tells the atom to do an atomic compare and swap operation. As the value used to calculate the green state is still the white value, the atom changes it state to the green value.
Now thread-2 finishes, when it tries to change the state of the atom, the compare and swap operation fails, because the atom is not longer pointing to the white state. So the thread-2 has to start again, but this time with the green value.
All this machinery about retrying and detecting conflicts is provided by the atom, so you as a developer only have to write a pure function.
Now to make sure that we all in the same page, I want to point out two things.
The first one is that the only valid values of the atom during the time were the white, green and red ones. Nobody ever saw the blue value.
The other thing is that if for example there was another thread, thread-3, that at time 0 read the current state of the atom and it keeps a reference to it for some time, as time moved, from t0 to t1 and t2, the thread-3 will still see the initial state, the white state. Because the value is immutable, nobody can touch it, which means that thread-3 can potentially be working with a stale value.
Now you may be wondering, wow, if I have to create a whole new graph every time that I want to change anything, isn’t all this immutability going to be extremely slow, extremely expensive? And in practice it is actually slower, but not as much as you would expect.
Lets say that you have this state,
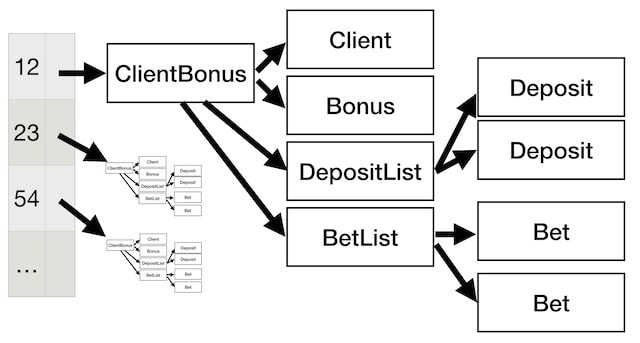
and to calculate the new state, you need to change some field in that bet object over there. Of course, you cannot change anything, so you create a new bet object. As the bet belongs to a BetList, and again everything is immutable, it also means that you have to create a new BetList, which also means that you have to create a new ClientBonus, and a new bucket on the hashmap.
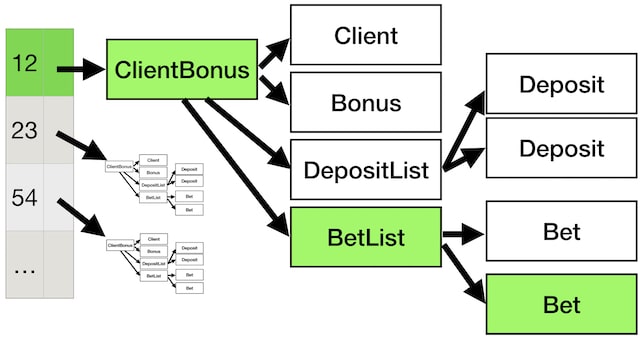
Those 4 things are what it is different between the green and the white state. So to build the green state you just need to create 4 new objects and you can reuse all the others, and you can do this because those objects are all immutable, and we know that it is safe to share immutable objects. This technique is call structural sharing.
Now, this is still slower that mutating one field in the Bet object, but the cost is still very cheap, specially if we compare it with the benefits of this approach.
Is this thread safe? Every Java developer, every day.
Have you ever ask yourself this question? With immutability and atoms, you still ask this question, but the rules to answer it are a lot simpler as they don’t involve the Java Memory Model and the “happens-before” semantics.

The first rule is that the state within an atom is always consistent, as everything is immutable, it is not possible to see half-baked states. This already removes a lot of the complexity in your code.
The second rule is that the function to calculate the new state must be pure, as it maybe run multiple times.
As we saw in the example with Thread-3, any decision that you make outside this pure function could be done with stale data or be subject of a race condition.
From this third rule, it should also be obvious that if you code has to look at two atoms to make some decision, the decision is not atomic.
So how all of this affected our Java code?
The first, obvious things, is that all the domain classes are immutable, so all the fields, including any map or list.
public class ClientBonus {
private final Client client;
private final Bonus bonus;
private final DepositList deposits;
…
Now for the state management part, we actually did not use an AtomicReference to store the whole map with all the ClientBonus.
In our case, as what one client does, do not affect the outcome of another’s client bonus, our application logic just really needs the ClientBonus to be consistent, it doesn’t need a consistent view of all current ClientBonuses.
So what we did was to actually use a ConcurrentHashMap to hold the state, and then each value will get its own little machinery to advance time.
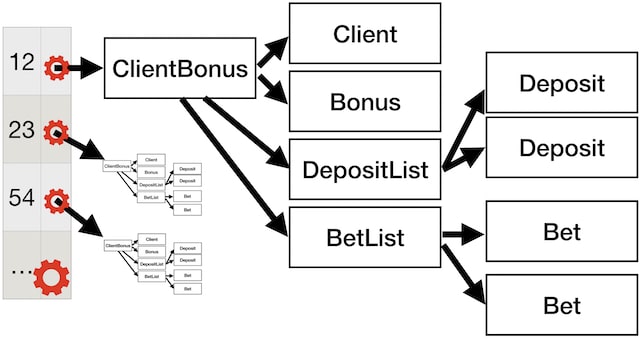
That machinery is provided by the compute family of methods of the ConcurrentMap, which basically provide the same semantics as Clojure’s atom, but on a per key level.
public interface ConcurrentMap<…> extends Map<…> {
V compute(K key, BiFunction<…> remappingFunction)
V computeIfAbsent(K key, Function<…> mappingFunction)
V computeIfPresent(K key, BiFunction<…> remappingFunction)
…
}
So this is how the class that hold the state would look like.
public class TheStateHolder {
private final Map<Long, ClientBonus> state = new ConcurrentHashMap<>();
public ClientBonus nextState(Long client, Bet bet) {
return state.computeIfPresent(
client,
(k, currentState) -> currentState.nextState(bet));
}
It contains the ConcurrentHashMap, and every time that the application gets new data, it just calculates the new state in an atomic way.
In our case, we decided that the ClientBonus itself should be the one that calculates the new state,
public class ClientBonus {
...
public ClientBonus nextState(Bet bet) {
...
}
…
so that nextState function must be a pure function.
So this way we managed to separate state management from application logic.
Effects
So now that we know how to fight State, let’s look at what we can do with effects.
Effects are actions that our application has to do in order to change the state of the external world.
In our case, those effects were things like sending a notification to the user about the progress of the bonus, or paying the price into the client’s account.
Clojure, the same as Java, is not a pure language like Haskel, so it actually does not provide any special tools to deal with IO. So lets see how we can handle effects.
Typically, in our applications, we would have something like this. Some kind of service object that depends on some interface and then at runtime we inject some dependencies.
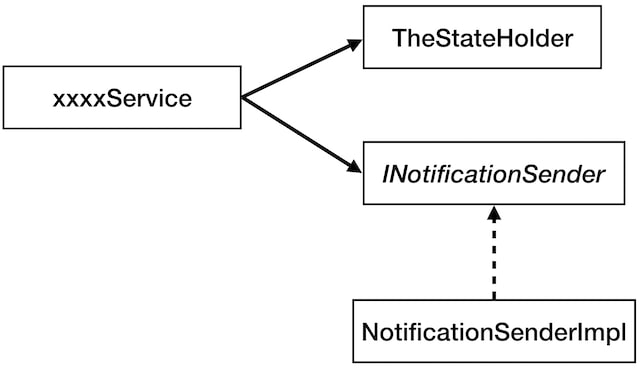
If you think about what this kind of service looks like, you will notice that is it takes care of two things: it decides which side effects our applications has to do, plus it has to execute those side effects and deal with any possible errors or exceptions raised by doing the effects. So when you write the code for the service, you have to keep in mind both things.
So if we want to follow a more functional approach, we want to separate those two things, so we can work on them independently. On one hand, we want to decide what effects need to be performed, and in the other hand we have to deal with the messy and ugly details of interacting with the external world.
To decide what effects need to be performed, in our business logic, we can instead of calculating the next state, we can also calculate the effects. With this, calculating the effects to be performed becomes part of our pure business logic, becomes part of our pure function.
public class ClientBonus {
...
public Pair<ClientBonus,Effects> next(Bet bet) {
...
}
…
Note that this also means that our effects become explicit first-class concepts in our application.

This would be an example of a class representing the effect of notifying a client about the progress of a bonus.
Now, even if another part of the system is going to be executing this effect and dealing with errors, our business logic can still decide on how the effects and the errors are going to be handle.
For example, in our business logic, we could be wrapping this effect in a Ignore error policy, while in other cases, maybe it could decide that the correct policy is to stop the JVM.
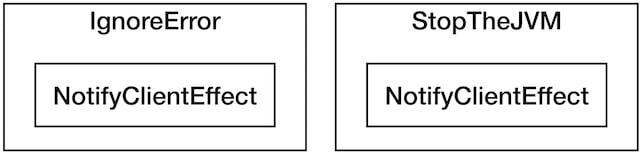
Apart from the error policy, the application logic can also decide if the effects must be run sequentially, so if one fails, the rest will to be not executed.

or that maybe the effects are independent, so that an error in one should not affect the others, which also could mean that the effects can be executed in parallel.
For our bonus application, we decide to not build any of these flexibility in the effects, as we thought it was not necessary, and instead we went to have a very rigid, very static, way of defining the effects, and encode in the type system what were the valid and possible chain of effects.
But now that we have a description of what side effects must be run, we still need to execute them, we still need to run them, so some piece of code needs to go and interpret this description of the chain of effects.
In our case, as the structure of this description was very rigid, we opted to just let each effect know how to run itself.
public interface Effect {
void run(AllDependencies dependencies);
}
Note that it is here were we pass all the dependencies required to execute those side effects, things like the http or JMS clients.
Passing that AllDependencies object around has the benefit that it makes very obvious which methods are impure, because to be able to perform any side effect, the method would need to declare that dependencies object as a parameter.
It has the drawback that sometimes it is a little bit cumbersome to pass it around, and that the AllDependencies class is quite ugly, as it has to hold, and make accessible, a lot of dependencies. That AllDependencies class feel almost like your Spring Context.
So this is how our code would look like:
Pair<ClientBonus, Effects> pair = theStateHolder.nextState(bet);
pair.effects.run(dependencies);
We calculate the next state and the effects to perform, and then we will perform those effects.
But the question is, is this thread safe?
With the rules that we saw before regarding atoms, it is obvious that it is not, because one of the rules was that anything that happens outside that pure function that calculates the new state, could be subject of a race condition.
And were is the race condition here?
So let’s say that two threads come and calculate the new state and the effects to perform.

The atom takes care that those two threads make a decision that is atomic, consistent and isolated. So far, so good.
But now that we are outside the atom mechanism, we are subject to possible race conditions, so it could be that the thread-2 performs its side effects before thread-1.

And this may, or may not, be acceptable, depending on your business requirements.
So, atoms do not make all race conditions go away, but they should make it a lot more obvious of when they could happen.
If in your application this kind of race condition is not acceptable, a possible option could be to use an Agent.
Clojure Agents are basically like an atom, but it gives you the additional guarantee of being single threaded. If you are familiar with actors, they are a little bit like actors, in their concurrency model.
For our bonus application, this kind of race condition was not acceptable, but we decided to not use Agents, and stick with atoms, why?
Well, we were running multiple instances of the bonus service, so we are now in the realm of distributed system programming.
As the side-effects that our application needed to perform, could not be done in an atomic way, the distributed system theory tell you that you must chose between at-least-once or at-most-once semantics.
In our case, we look at each effect and for each one, we decided what was more appropriate. For those that were at-least-once, we did no coordination, nothing.
For the ones that required at-most-once semantics, we used a relational database as the coordination mechanism, as the DB provides ACID guarantees.
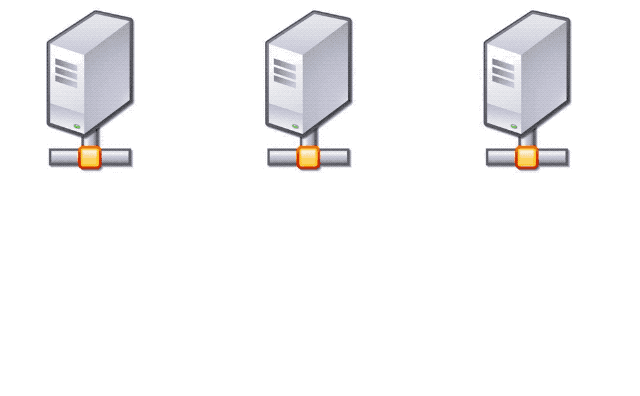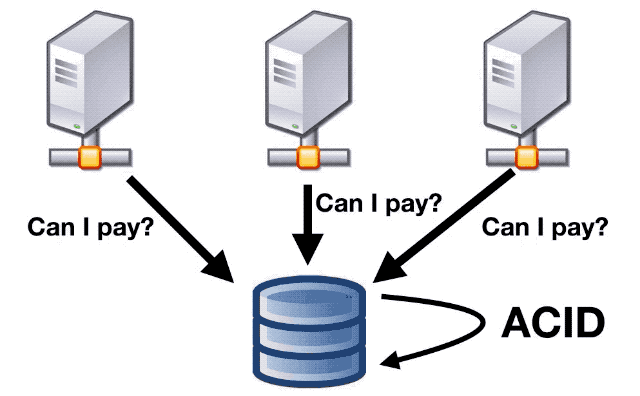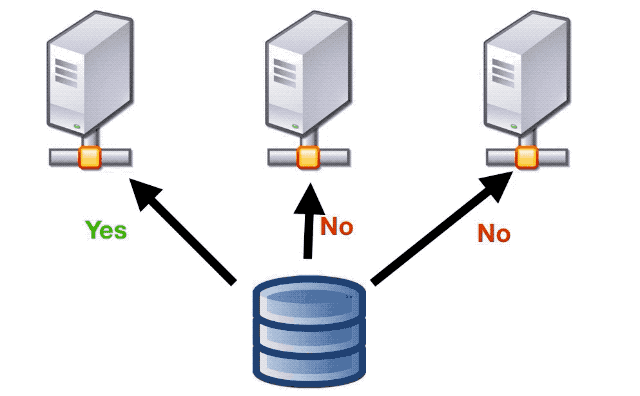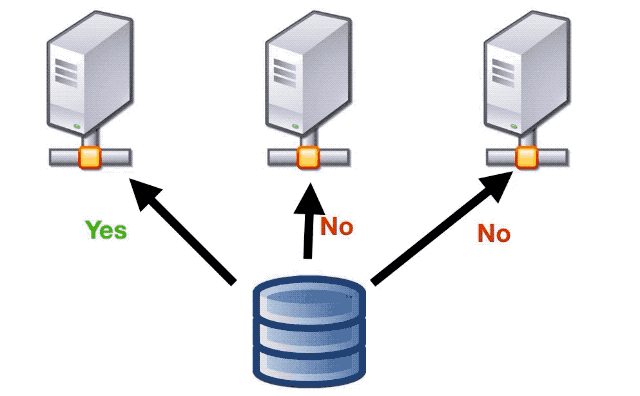
So before doing one an effect that required at-most-one semantics, the application will check with the DB, so that if there was a race between several instances to perform the same effect, only one will get the go ahead and execute it.
Note that it was still our pure functions, the ones calculating the effects,
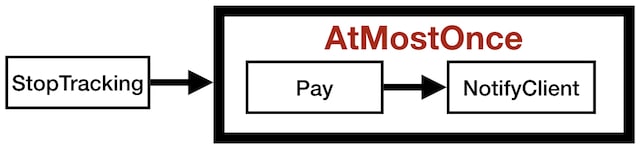
the ones that would decide when and which effects needed at-least-once or at-most-once semantics, and we did by wrapping the effects in a “at-most-once” policy.
Co-Effects
The last type of side effect are the co-effects. Co-effects are the inputs, the data, that our application needs to make their decisions.
For our bonus application, we basically needed 4 pieces of information: which clients have sign up for which bonus, the bets and deposit made by the client, and as the client has a limited amount of time to achieve the bonus, we also need to know what time it is.
As I hinted before, we kept all of our state in memory, and we were able to do this because the input source of the client events, was Kafka. If you are not familiar with Kafka, you can think about it like an immutable message queue, that remembers all the message go through it.
So that when the bonus application started, it will ask Kafka for all the messages in the last couple of months, and recalculate the current state from all those events. Also, each event would be timestamped, so the application will use the event time as the current time in its logic.
This is basically Event sourcing. At its heart, Event Sourcing and functional programming share a lot in common.

Event sourcing and functional programming go hand in hand.
Benefits
So this is how the whole thing looks like if you put everything together
public class KafkaConsumer {
private AllDependencies allDependencies;
private TheStateHolder theStateHolder;
public void run() {
while (!stop) {
Bet bet = readNext();
Effects effects = theStateHolder.event(bet);
effects.run(allDependencies);
}
}
…
}
These are two dependencies that will be injected by your dependency injection framework of choice.
The object with all the dependencies required to do effects, and the state of the application.
Here we are using the Kafka polling api, so the KafkaConsumer will be a Thread that will be reading new events from the Kafka topic.
Then ask our state to advance time, update the state and to return the effects that we need to execute.
And last we ask the effects to execute themselves.
By following this approach, some interesting things happen to our code:

First, our business objects had 0 getters or setters.
Also, our business logic was cleaner, because it will have no locks or synchronised methods, no try/catch blocks and no logging, because all of these will be done in a different part of the system. This removed a lot of noise from out business logic.
Also, there were no mocks in our unit tests, as both the inputs and outputs of our business logic where all plain values, so our unit tests were simpler. To test the side effects, all the impure parts of the codebase, we decide to use a small number of full-stack or integration tests.
And last, because we did not have to mock anything, we did not had any useless interfaces in the codebase. By useless interface, I mean those interfaces that just have one production implementation.
Functional core, Imperative shell
Now this style of design or architecture is called functional core, imperative shell.
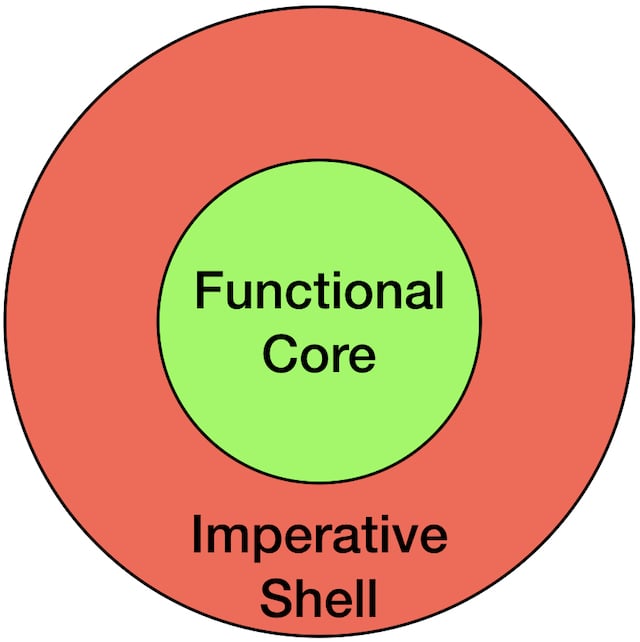
The functional core is where all of our pure functions live, it is devoid of side-effects. The functional core is where we try to make as many decisions as possible, as it is easier to test and to change.
The imperative shell is where all the side effects live, all the ugly code about error handling, state and IO. We try to devoid the imperative shell from any conditionals, from any decisions.
And the aim is to try to make the functional core as big as possible, while we make the imperative shell as thin as possible.
As there are other architectures that have the same circular shape, I want to make something very clear.
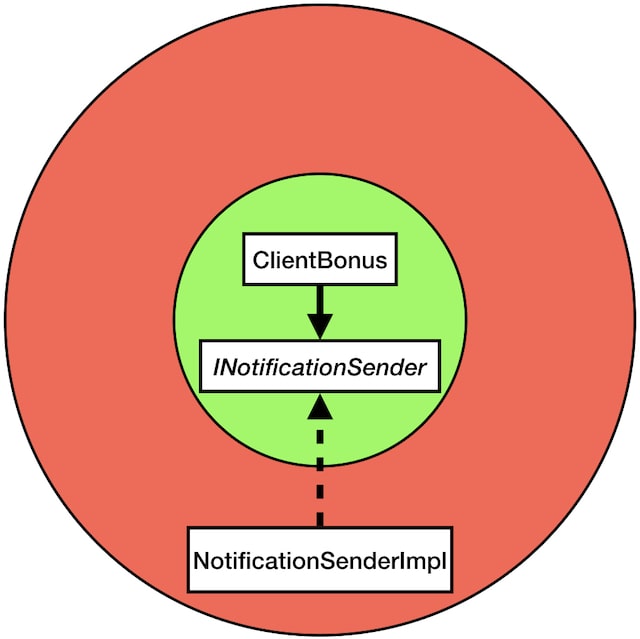
If you have some code like this, where your core class depends on some interface also in your core package, and then you inject the actual implementation at runtime, this piece of code in ClientBonus is not functional. You functional core cannot dependent on any piece of code that could do a side-effect, not even on an indirect way.
Now I am not saying that you shouldn’t do that, I am just pointing out that when you do this, all this code belongs to the imperative shell, so you do not have the benefits of your functional core.
Dynamic (vs Static) typing
Lets talk about the next big difference. Clojure is a dynamic language, while Java is a static one.
This is how a typical Clojure program looks like:
clientBonus = Map.of(
"client", Map.of("id", "123233"),
"deposits",
List.of(
Map.of("amount", 3,
"type", "CASH"),
Map.of("amount", 234,
"type", "CARD")));
((List) clientBonus.get("deposits"))
.stream()
.collect(
Collectors.summarizingInt(
m -> (int) ((Map) m).get("amount")));
First, our domain objects are just a bunch of maps and list. And then our business logic consists on manipulating those maps and lists.
I am not sure what do you think about this, but for my Java sensibility,
this is just hell, this code is the exact definition of unmaintainable code. If anybody in my team wrote that piece of code, I would demand for a very very good explanation of why are they doing it.
So in our bonus application, we decided to not do this at all, so we did not bring Clojure’s dynamic typing, and just use the Java type system.
But when you are writing Clojure code, surprisingly, this dynamic typing is less of an issue, and I think it is because the Clojure core api is tailor to work with this dynamic data structures, so is a lot less hassle than with the Java API.
But once you have write enough Clojure code, your mind starts to dysfunction, and then when you come back to Java, you start to have really weird thoughts.
So when you type this class,
public class Bet {
private String id;
private int amount;
private long timestamp;
}
you start to wonder, well, what is the value of creating a new class? What do I get out of this instead of using a plain map?
And you notice that the first thing that you get is an almost useless toString method, you also get a broken equals and hashCode implementation. That is really annoying, but at least we have Lombok.
But what do you lose? Suddenly, you lose all the functionality that comes with maps, all of it, but what is worse, all the code that you have that works with maps, that understands maps, will not work with this new class. You have no code in the Java core API that can work, that can do anything, with this class. Except maybe for the reflection API.
What is more, how many libraries are you going to find in Github that work with this new class? None.
It is at this point when you start to understand what Alan Perlis meant with
It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures. Alan Perlis
Each new class is a new data structure, that comes with zero functionality, that is completely isolated from any other code. This hampering the reusability of your code.
But what if we just leave our Bet objects as plain data?
{:type :bet
:id "client1"
:amount 23
:timestamp 123312321323}
You have a sensible toString, the one that you see there.
You also get a proper equals and hashCode for free.
But what is more important, you can still use all the core functionality that comes with your programming language, so you don’t start from scratch, you can reuse a lot of code. and you will find Github libraries that work with this code.
The Clojure community has embraced idea this idea of using plain data to represent as many things as possible.
For example, you can use plain data to represent an http request, so what your http servers have to do is work with this map as an input
{:request-method :get
:uri "/foobaz"
:query-params {"somekey" "somevalue"}
:headers {"accept-encoding" "gzip, deflate"
"connection" "close"}
:body nil
:scheme :http
:content-length 0
:server-port 8080
:server-name "localhost"}
and just generate another map as an output. And you will do this by using the same core api.
{:status 200
:headers {"Content-Type" "text/html"}
:body "Hello World"}
Think how much easier your test would become.
But also, you can represent other things as plain data.
Sql queries:
{:select [:id :client :amount]
:from [:transactions]
:where [:= :client "a"]}
and the database result sets:
[{:id 1 :client 32 :amount 3}
{:id 2 :client 87 :amount 7}
{:id 3 :client 32 :amount 4}
{:id 4 :client 40 :amount 6}]
HTML and CSS:
[:html
[:body
[:p "Count: 4"]
[:p "Total: 20"]]]
Configuration:
{:web-server {:listen 8080}
:db-config {:host "xxxx"
:user "xxxx"
:password "xxxx"}
:http-defaults {:connection-timeout 10000
:request-timeout 10000
:max-connections 2000}
:user-service {:url "http://user-service"
:connection-timeout 1000}}
Even data about your data, your metadata:
{:id :string
:name :string
:deposits [{:id :string
:amount :int
:timestamp :long}]}
So by embracing this idea of using plain data, you end up using the same core API to write
- your business logic
- your infrastructure code
- your configuration
- your metadata.
Just one API that you need to learn and master.
So dynamic typing in Clojure is not as bad as you would expect, as it is brings a big chunk of benefits.
Dynamic (vs Static) development
But types is just one of the dynamic vs static differences between Clojure and Java. Clojure provides a dynamic development experience. What does this mean? In Clojure, the first thing that you do when you have to develop a new feature is to start your application, and then what you do is just keep changing that running application, until you are done, without ever stopping it.
You do this by using a REPL.
Of course Java now has something call a REPL, but

just because they both have the same name, it doesn’t mean that they are the same.
With a proper REPL, you never build or start your application, you grow the application from inside, one tiny bit at a time.
A proper REPL gives you the same feeling, the same ergonomics, as a Unix Shell.
A proper REPL is like having a debugger all the time attached to you running JVM.
A proper REPL is the missing piece on your test-driven-development workflow.
This talk is my best attempt to explain what a REPL is, but I think that a REPL is one of this very very alien things, that you really need to experience it, because it is very hard to understand or imagine.
A proper REPL is the thing that I miss the most when working with Java.
Lisp (vs Fortan)
Ok, last section of the talk.
For our bonus project we obviously did not use the Clojure syntax, because if I did, I wouldn’t be here giving this talk.
But for all of you that run away screaming whenever you see some Lisp, I have some good news for you.
The first thing is that, like other modern JVM languages, in Clojure you don’t have to type semicolons! This, I think we all agree, is a huge improvement over Java.
In fact, this feature is so awesome, it is such a huge productivity boost, that Clojure goes even further, and in Clojure, commas are optional! Think about all those millions and millions of commas that you have typed.

Imagine if you could get all that time back, I would be at least 20 years younger.
But I know what you are thinking

what about all those parenthesis that Lisps is infamous for? Well, even here I have good news for you.
.filter(removeCsvHeaders(firstHeader))
.map(splitCsvString())
.map(convertCsvToMap(csvHeaders))
.map(convertToJson(eventCreator))
(filter not-header?)
(map parse-csv-line)
(map (partial zipmap headers))
(map ->event)
Those are two pieces of code from one of my teams. When we were learning Apache Spark, we happen to write basically the same application both in Clojure and Java. This is the main logic of the application, and as you can see they are the same, but there is an important difference.
Let’s count parenthesis. 1, 2, 3 … The Java version has 16 parenthesis. And how many does the Clojure one has? 10. So the Clojure version has 40% less parenthesis.
But not only that, the Clojure version of the application, had one tenth of the code.

One tenth, imagine if you could delete 90% of your code.
Ok, enough of silly jokes. Let’s look at why Lisp people are so in love with their parenthesis. For this, I am very sorry, but I am going to have to show you some more Clojure code.
List.of(
new Symbol("defn"),
new Symbol("plus-one"),
List.of(
new Symbol("a"),
new Symbol("b")),
Map.of(
new Keyword("time"), List.of(new Symbol("System/currentTimeMillis")),
new Keyword("result"), List.of(
new Symbol("+"),
new Symbol("a"),
new Symbol("b"),
new Long(1))));
This is a typical Clojure program. We are defining a function that takes two parameters and returns a map with the sum of those parameters, plus one.
Ok, maybe Clojure is a little bit less verbose than this, but this is essentially what you are doing when you write, when you type Clojure. What is this? Your code are just lists and maps, this is what we mean when we say that in Lisp, code is data, because look at this, it is actual data.
And because it is data, we can manipulate it, we can generate it, we can analyse it, with exactly the same tools, the same api, that we use for our Business logic, our infrastructure code, our configuration.
Metaprogramming, so writing programs that write programs, becomes a matter of working with lists and maps. This is very simple, yet extremely powerful.
This is why Lispers love their parenthesis so much.
Summary
So in summary …
Try to write as many pure functions as possible, they will make your application easier to understand and easier to change.
After using Clojure, I see the dynamic vs static typing as a trade off. It is true that in Clojure I miss some of the refactoring capabilities that I get with a good Java IDE, and that I sometimes waste time chasing some misspelt word, but Clojure’s focus on data, somehow, makes the trade off a fair one.
But after enjoying Clojure’s dynamic development experience, this is something I would never ever want to let go.

And please do not be scared about parenthesis. The same way you would not write Java without an IDE, you will not write Clojure without one. And the IDE is going to take care of all those scary parenthesis. And remember that there is a very good and powerful reason for them.
I want to finish with another quote by Alan Perlis:
A Language that doesn’t affect the way you think about programming, is not worth knowing.
Clojure has been, for me, one of those languages. Immutability by default, functional programming, dynamic typing and the repl, Lisp syntax and macros, everything as simple data.
All those things have been big lessons for me. They have change the way I approach problems, they have change the way I build applications, they have change the way I design systems.
But none of those has been Clojure’s most important lesson.
The key insight, the most profound lesson on my journey learning Clojure, has been that I have been how close minded I have always been to different ideas, just because of the fact that they were different to what I was used to.
If any of you had told me 5 or 6 years ago to learn a dynamic lisp, I would had say “no way, I am not going to waste my time”. And yet, here I am, preaching about Clojure.
Clojure has open my mind to be curious about different ideas, even those that initially may seem disgusting.
So I want to encourage everybody to learn this year, or next year, a new language, and it doesn’t need to be Clojure,

but pick something completely different to what you are used to, something that makes you uneasy, something completely alien.
I am sure that on that journey, you will learn something that you will want to bring to your day to day job.
And in the worst case,

it will just make you weirder and harder to relate to.
Thanks a lot for you time.
But before you leave, please have a quick look at this video: