
Intro to Machine Learning & NLP with Python and Weka
In this tutorial, you’ll be briefly introduced to machine learning with Python (2.x) and Weka, a data processing and machine learning tool. The activity is to build a simple spam filter for emails and learn machine learning concepts.
This article is written by the Codementor team and is based on a Codementor Office Hours by Codementor Benjamin Cohen, a Data Scientist with a focus in Natural Language Processing.
What is Machine Learning?
In a nutshell, machine learning is basically learning from data. Way back when before access to data was plentiful and access to computing power was plentiful, people tried to hand-write rules to solve a lot of problems. E.g., if you see {{some word}}, it’s probably spam. If there’s a link in the email, it’s probably spam. That worked all right, but as problems get more and more complicated, the combinations of rules start to grow out of hand, both in terms of writing them and in terms of taking them up and processing them. The number of techniques to do this all fall under the umbrella of machine learning. Basically you’re trying to automatically learn these relations from certain features in our data.
In machine learning, one of the big high level problems we’re trying to solve is called classification. Simply put, it decides what class to put something in. For example, classifying if some email is spam or not spam, or if a picture as a dog or a cat. Anything that divides splitting up data into two or more classes.
That said, what we’re really going to be developing here is a system to automatically differentiate between two or more classes. In the case of this exercise, spam or not spam. We want to do all this without having to manually tell the computer our rules. One of the things that’s necessary for this and any machine learning problem is a dataset. The general process is for the machine to learn rules from our dataset (which we hope represents what all datasets look like), and then use what it learned on new data. In other words, without a dataset as a backing to tell the machine what’s correct and what our data look like, we can’t develop the rules for the machine to learn from. We need materials for the machine to learn from.
On a side note, we’ll be going into this activity already prepared with a dataset. However, when you’re approaching a problem in general, you often don’t have data yet, and you don’t know what data you need.
If you were to write a system to identify spam emails, the data set we use in this exercise is the kind of data you’d want, but in real-world apps you might want to find out another dataset to cross-reference. Email addresses are kind of shaky as spammy addresses often get shut down so they create a lot of new email addresses. One thing you could potentially do is judge the domain name’s probability to send spam email. For example, not many people use gmail for spam because Google is great at detecting and shutting down spam email accounts. However, some domains such as hotmail may have a pattern where if the sender is using hotmail it’s more likely to be spam, so you can definitely see if you can learn from examining email addresses. Another classic feature we could look at is meta information, such as what time the email was sent. All the data we’ll look at in our activity is what was actually in the email i.e. the text.
The Exercise
Here is the link to the GitHub project you can fork and use along with this activity, and make sure you have installed Weka in your machine – it’s a free software.
The dataset we’ll be using here contains roughly 1300 emails. You can quickly browse through the two folders we have, is-spam and not-spam to see what emails we have.
For example:
Find Peace, Harmony, Tranquility, And Happiness Right Now!<html><head></head><body bgcolor=3Dblack>
<table border=3D0 cellspacing=3D0 cellpadding=3D5 align=3Dcenter><tr><th b=
gcolor=3D"#8FB3C5">
<table border=3D0 cellspacing=3D0 cellpadding=3D5 align=3Dcenter><tr><th b=
gcolor=3D"#000000">
<table border=3D0 cellspacing=3D0 cellpadding=3D0 align=3Dcenter>
<tr>
<th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D=
pw">
<img src=3D"http://giftedpsychic.com/images/r1c1.jpg" width=3D279 height=3D=
286 border=3D0></a></th>
<th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D=
pw">
<img src=3D"http://giftedpsychic.com/images/r1c2.gif" width=3D301 height=3D=
286 border=3D0></a></th>
</tr>
<tr>
<th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D=
pw">
<img src=3D"http://giftedpsychic.com/images/r2c1.jpg" width=3D279 height=3D=
94 border=3D0></a></th>
<th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D=
pw">
<img src=3D"http://giftedpsychic.com/images/r2c2.jpg" width=3D301 height=3D=
94 border=3D0></a></th>
</tr>
</table></th></tr></table</th></tr></table></body></html>
is a pretty typical spam email, while
Re: EntrepreneursManoj Kasichainula wrote;
>http://www.snopes.com/quotes/bush.htm
>
>Claim: President George W. Bush proclaimed, "The problem with
>the French is that they don't have a word for entrepreneur."
>
>Status: False.
>Lloyd Grove of The Washington Post was unable to reach Baroness
>Williams to gain her confirmation of the tale, but he did
>receive a call from Alastair Campbell, Blair's director of
>communications and strategy. "I can tell you that the prime
>minister never heard George Bush say that, and he certainly
>never told Shirley Williams that President Bush did say it,"
>Campbell told The Post. "If she put this in a speech, it must
>have been a joke."
So some guy failed to reach the source, but instead got spin doctor to
deny it. Wot, is he thick enough to expect official confirmation
that, yes, Blair is going around casting aspersions on Bush???
It's an amusing anecdote, I don't know if it's true or not, but certainly
nothing here supports the authoritative sounding conclusion "Status: False".
R
http://xent.com/mailman/listinfo/fork
is a normal email.
All in all, after quickly browsing through the folders, you’ll see they are pretty much representative of what emails that are and are not spam look like. This is really important because if our data doesn’t represent what we’ll see, the things the machine learns won’t make any sense.
To sum up the gist of our problem, we’re trying to determine features that will be able to allow us to differentiate the dataset in not-spam from the dataset is-spam. Hopefully this helps when we’re looking at future spam.
How does Natural Language Process Comes In?
If you’ve noticed, the emails from both is-spam and not-spam are text. Text and language are things that we as humans understand really well, but computers understand less well. We have to transform, in our case, this English language into things that computers can understand – which, in the general case, would be numbers. This is where the Natural Language Process (NLP) comes in, where we’re trying to get the computer to understand the gist of the context of these messages. The machine learning part of this is understanding patterns in the numbers and applying the patterns to future things.
What is a Feature?
A feature is basically some kind of transformation of our input into – in our case – a numeric feature, or just a number that our machine can learn from. We want to get a set of numbers, or a feature as we call it, that represents an email like this:
The DEBT-$AVER Program SKYXTGM<HTML><HEAD>
<META http-equiv=3DContent-Type content=3D"text/html; charset=3Diso-8859-1=
">
</HEAD><BODY><CENTER>
<A href=3D"http://marketing-fashion.com/user0205/index.asp?Afft=3DDP15">
<IMG src=3D"http://61.129.68.17/debt1.gif" border=3D0></A>
<BR><BR><FONT face=3DArial,Helvetica color=3D#000000 size=3D1>
Copyright 2002 - All rights reserved<BR><BR>If you would no longer like us=
to contact you or feel that you have<BR>received this email in error,
please <A href=3D"http://marketing-fashion.com/light/watch.asp">click here=
to unsubscribe</A>.</FONT></CENTER></BODY></HTML>
The better we can represent this email in numeric form, the more patterns we’d will hopefully observe from our emails if we pick good features.
Before writing any other features, we’re just going to straight-up look at the number of words. Here’s the code to do this in our features.py:
def numwords(emailtext):
splittext = emailtext.split(" ")
return len(splittext)
However, to let Weka analyze this data, we need to turn it into an .arff file.
There’s a script that I have called feature_extract.py. Right now you really don’t have to worry about what it is, but here’s the code if you’re interested:
import os, re
import math, glob
import features
import inspect
def main():
arff = open("spam.arff", "w")
ben_functions = inspect.getmembers(features, inspect.isfunction)
feature_funcitons = []
feature_funcitons += list([f[1] for f in ben_functions])
RELATION_NAME = "spam"
arff.write("@RELATION " + RELATION_NAME + "\n")
for feature in feature_funcitons:
arff.write("@ATTRIBUTE " +\
str(feature.__name__) + " REAL\n") #change this if we
#have non-real number
#values
###PREDEFINED USER FEATURES#######
arff.write("@ATTRIBUTE SPAM {True, False}\n")
arff.write("@DATA\n")
spam_directory = "is-spam"
not_spam = "not-spam"
os.chdir(spam_directory)
for email in glob.glob("*"):#ITERATE THROUGH ALL DATA HERE
extract_features(open(email).read(), feature_funcitons, arff, True)
os.chdir('../'+not_spam)
for email in glob.glob("*"):#ITERATE THROUGH ALL DATA HERE
extract_features(open(email).read(), feature_funcitons, arff, False)
def numwords(emailtext):
splittext = emailtext.split(" ")
return len(splittext)
def extract_features(data, feature_funcitons, arff, spam):
values = []
buff = ""
for feature in feature_funcitons:
value = feature(data)
values.append(value)
if spam:
buff += (",".join([str(x) for x in values]) + ', True' + "\n")
else:
buff += (",".join([str(x) for x in values]) + ', False' + "\n")
arff.write(buff)
if __name__ == "__main__":
main()
Basically this script applies all the features we’ve written in features.py and puts it into our .arff file.
So, after running feature_extract.py, let’s take a look at our spam.arff file:
@RELATION spam
@ATTRIBUTE numwords REAL
@ATTRIBUTE SPAM {True, False}
@DATA
1003,True
638, True
74, True
88, True
…
@Relation is just the name of our problem, and each of the @ATTRIBUTE is a feature. The first feature I have here is just the number of words, and REAL means it’s a real number. Our last attribute is the different classes, and in this case SPAM can be either True or False. After that, we just have our data, which contains the value of each attribute. For example, the line 1003, True means the email has 1003 words and is spam.
This .arff file is not something we’ll ever have to look at, as the file is just for us throw into Weka.
Run Weka and load up the spam.arff file.
You’ll see that in the prepocess tab, the left column contains all of our features. If you click “SPAM”, we will see the distribution of spam or not in the right column. You can see that of our 1388 emails, 501 are spam while 887 are not.
Let’s look at numwords with Weka:
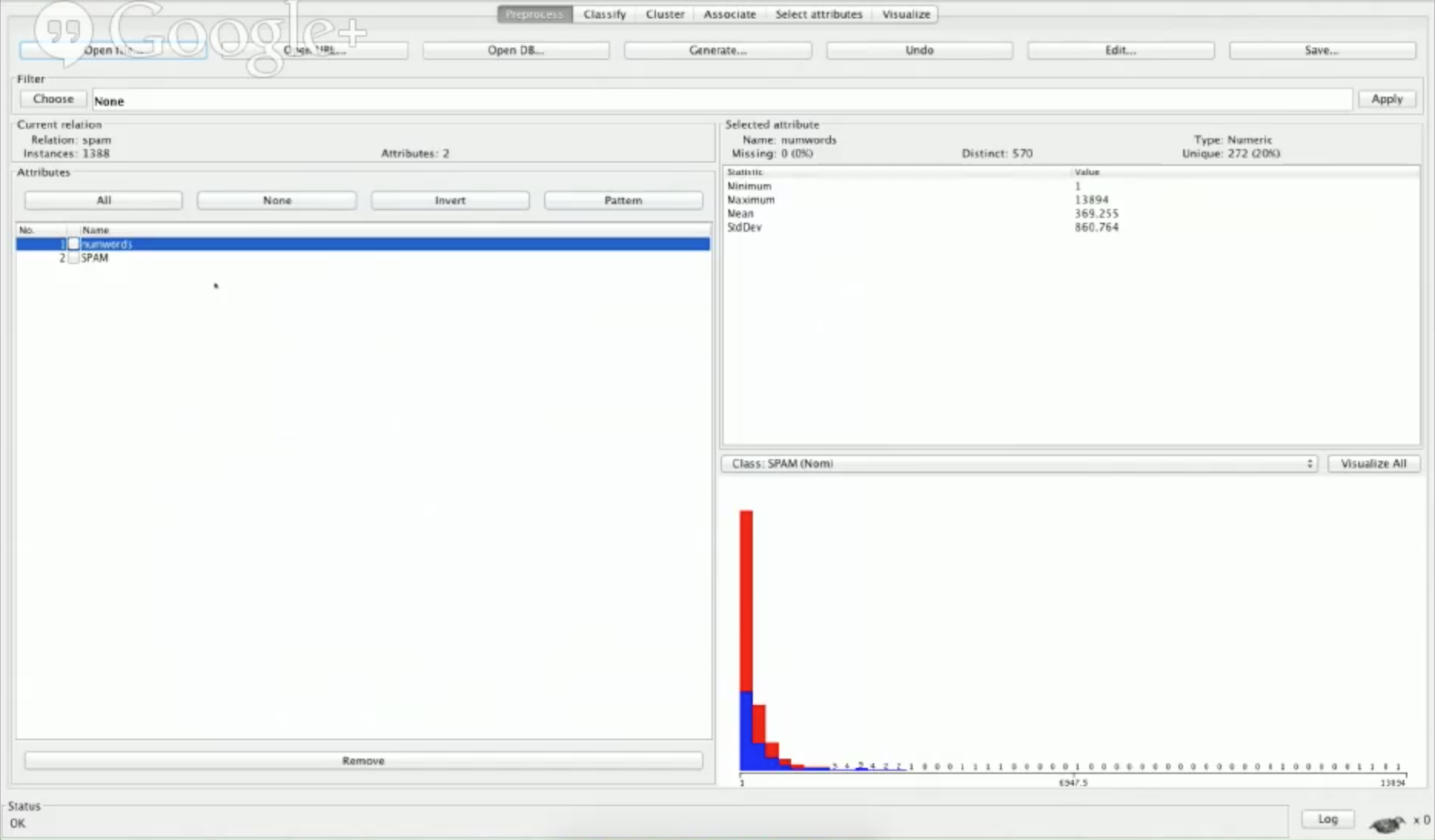
You’ll see that we have a distribution that doesn’t tell us a whole lot right now, and we also have some statistics. For example, the fewest number of words is 1, and the maximum is 13894, which is very high. As we get more features, we can see more difference in distributions and tell which ones are good and not good.
How to Choose, Make, and Use Features
The next important thing we have in Weka is the Classify Tab.

There’s a lot of information in this tab, but we’ll temporarily ignore most of them in this activity. One of the big things we’ll use is the classifier box, in which a classifier is basically how we try to learn patterns. Depending on your problem, certain classifiers will work better for certain problems. If you click on the classifier box, you can see that things are grouped into different categories that can be expanded.

Then, we have our test options. We want to not only train the models, but we need some way to see if the pattern we’ve learned or observed from our feature is good. We could learn a pattern, but if it proves to be totally useless, that’s not very helpful to us.
In our Test options, we’re going to use a Percentage split.

An 80% percentage split will train a model on 80% of our data. In our case, roughly 1000 of 1300 emails. The remaining 20% will be used to test out the model, and we’ll try to see what percentage of those we’d get right.
We want to use a percentage split because we don’t want to run into a problem called “over-fitting”, where we learn trends in our training data that might not exist in the real world. If we learn a very specific set that occurs by chance in our training data, it doesn’t really tell us anything about the pattern, since the pattern might not be observed in other data. It’s important to keep in mind that we always want to test on data we haven’t seen before so we can simulate having real-world data to test our pattern on, rather than testing on the same data we train with.
We’ll eventually go over an example of over-fitting, but let’s first take a look at how our numwords feature performs by choosing a rule called OneR and running a test:
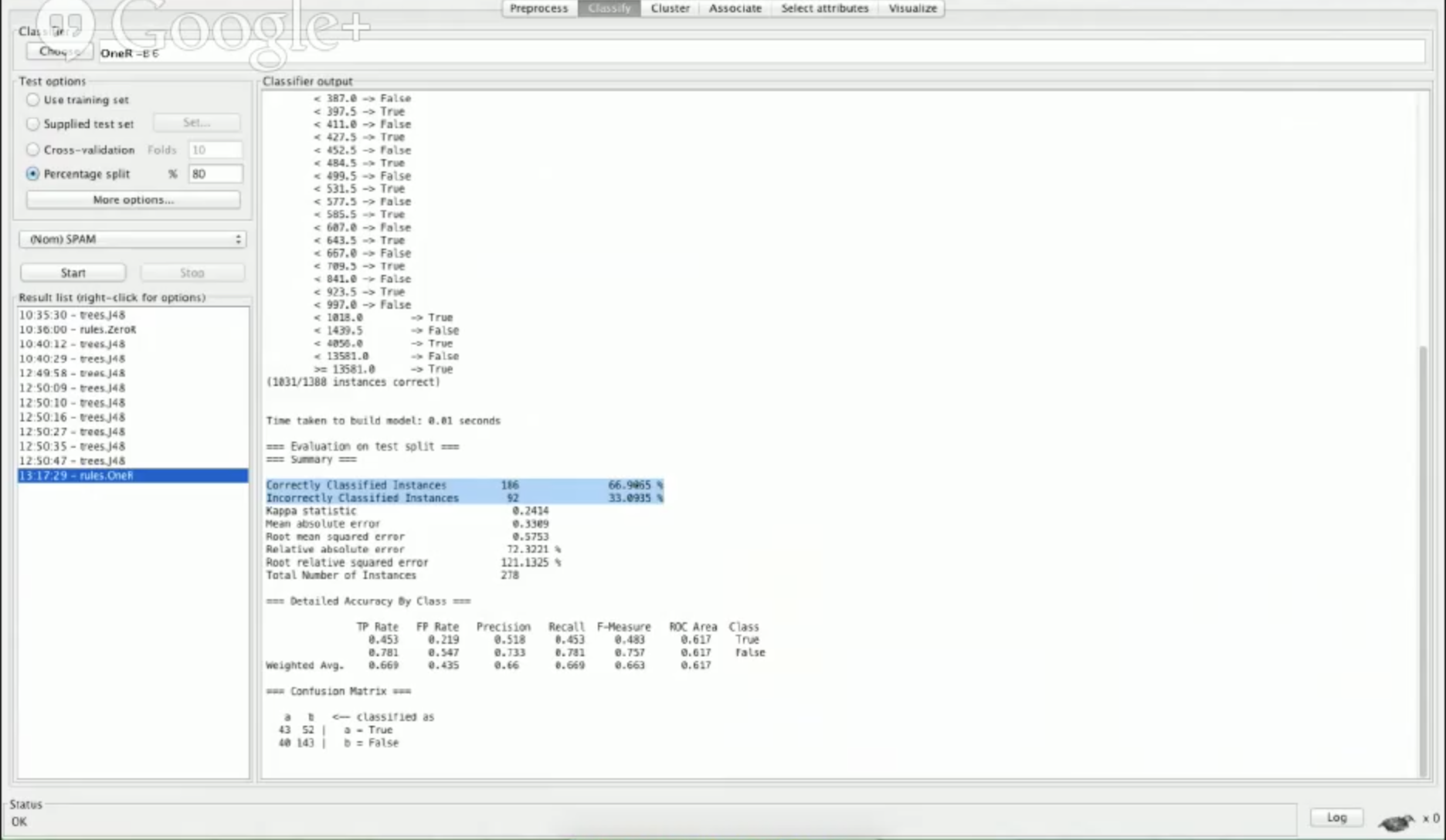
The biggest number we’re going to pay attention is the “correctly classified instances”:
Correctly Classified Instances 186 66.9065 %
Incorrectly Classified Instances 92 33.0935 %
These numbers represent our spam detection accuracy. You can see that, using the features we have, we classified 66.9% of our emails correctly as spam or not-spam. On first inspection, this looks great progress.
However, 66.9% accuracy is not that great because if we look at our initial data distribution, we have 1388 emails, and of them 887 are not spam, or roughly 64% are not spam, so 67% accuracy is not much.
The concept that has been illustrated is called a baseline , which is the super simple classification we use to compare all of our other results. If our distribution was 50:50 of spam and not spam and we got a 66.9% accuracy, that would be really great as we’ve improved by roughly 17%. Here we’ve only improved by 3%.
What is a Confusion Matrix?
Another thing to look at is the lower part of the Weka at our confusion matrix:
=== Confusion Matrix ===
a b <— classified as
43 52 | a = True
40 147 | b = False
The “a b” row represents the predicted class, while the “a b” column represents the actual class. Here, a is when spam = True, while b is spam = False.
So, of a we’ve classified 43 correctly, while we’ve incorrectly classified 52 as b, and in this case spam or not-spam. The bottom row shows our confusion, or what we got wrong.
This confusion matrix is helpful, since if we had 0 in the bottom-left corner, we’d know that we classified everything in is-spam right, but it will also mean we’ve been classifying too aggressively and should lighten up our rules a bit by tweaking our parameters.
Improving Weka’s Classification Accuracy
To improve our accuracy, let’s hop back into our features.py and write some code to get more features.
Currently we have a feature that gets the entire text of the email and return a number of words. Again, this will automatically be incorporated into our spam.arff file via our features_extract.py script. Now we will add a feature that checks if the email is in HTML or if it’s just plain text.
I chose to add this feature because I know it will give us an interesting distribution. You can generally come up with ideas for what features to add by manually looking at your dataset for patterns. As you scroll through a number of emails in our not-spam folders, you can see that few of the normal emails appear to be formatted in HTML. In our is-spam folder, some of our emails seem to be in HTML, so this might be a good feature.
As this activity will take less than an hour, we’re only going to be writing an approximation instead of writing a perfect way to check whether an email is in HTML or not.
def has_html(emailtext):
return 1 if "html" in emailtext.lower() else 0
This assumes that the email is HTML if the word html shows up, which again may not be the case, but it’s simplistic.
After we run our features_extract.py script in our console with
python feature_extract.py
We’ll re-open our .arff file with Weka and see that it will have our has_html feature:

The mean and standard deviation don’t mean too much here. Taking a look at our graph, based on the SPAM feature, the red represents emails that are not spam. So we can see that based on our has_html feature, the majority of not-spam do not have HTML, and the majority of our is-spam email do have HTML. This is just what we expected, and this shows us – at least from visual inspection – we can learn something from this feature, so this is a good feature.
Let’s go ahead and write a third feature in features.py. Based on the dataset, I’ve observed that spam seems to have more links in them as they want you to buy something, so I want to return the number of links.
def num_links(emailtext):
return emailtext.count('http')
Again this is just an approximation and we’re not looking for the exact number of links as it’s more time-consuming. The feature above basically assumes that whenever the email mentions http, it corresponds to a link.
After running our features_extract.py again, we can re-open our spam.arff file on Weka:
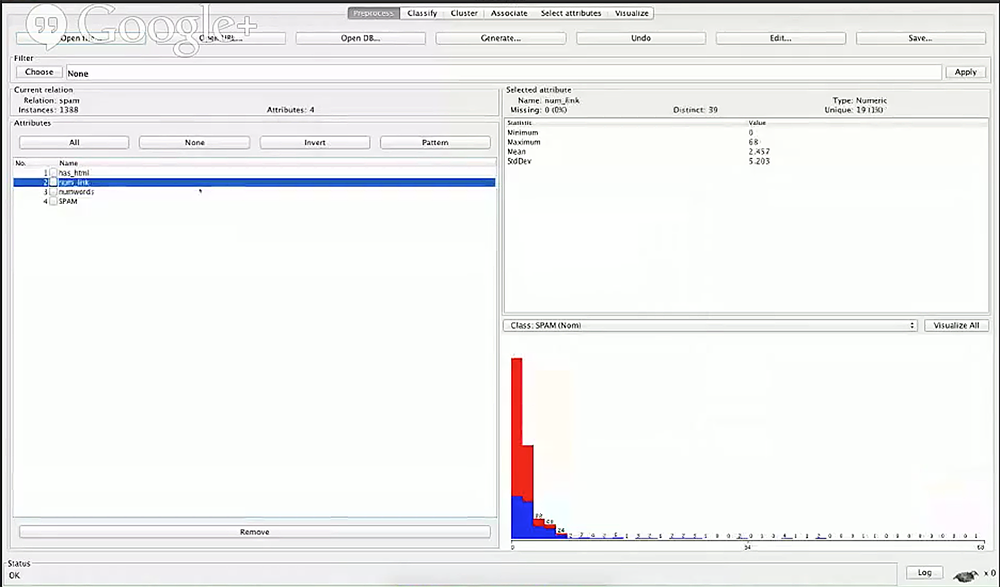
As expected, we see our minimum is 0 as there are emails with no links, and one email actually had 68 links in it.
Interestingly, if you look at our distribution graph, at some point (about 10), all our emails with over 10 links are spam, so this seems to be a really good feature. Now we can have a rule where if the number of links is greater than 10, we can say that it’s definitely spam, and a general rule where the more links an email has, the more likely it’s going to be spam.
Let’s take a look at our classify tab in Weka and see what these features do for our classification accuracy by re-rerunning our test.
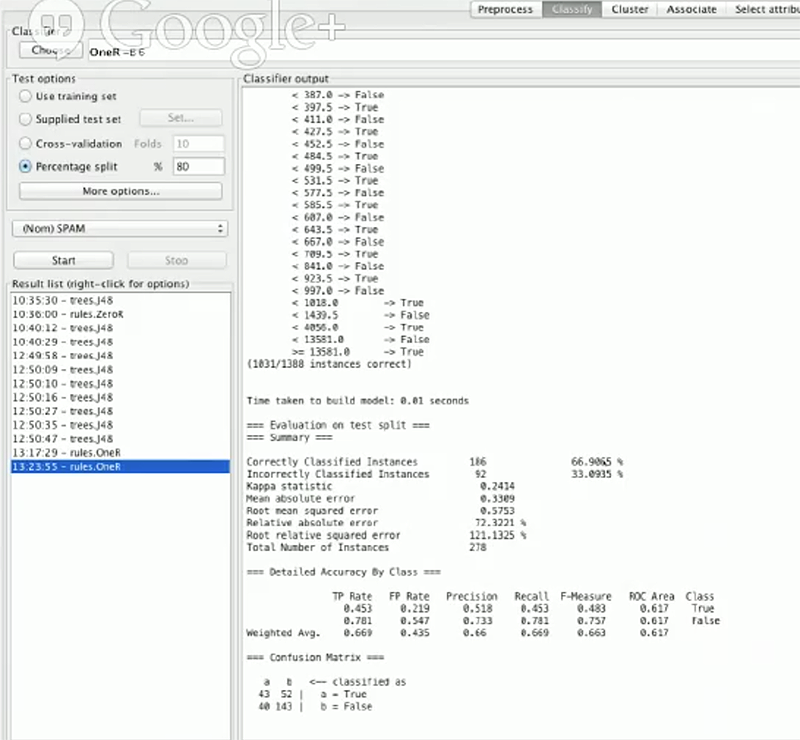
It looks like nothing has changed, even though we have new rules that are supposedly much better, and the reason for this is that we used the wrong classifier. OneR classifier only looks at one feature and develops rules based on that, so even if we re-run the test, it’s only looking at the feature numwords and making a whole lot of rules based on that. However, we have 3 features now and we’re not so sure classifying based on the number of words is good, but we know that has_html and has_link are good and we want to incorporate all of them. Let’s switch our classifier to a decision tree, J48.
What is a Decision Tree?
A decision tree is an easy concept very similar to what we do as a human, since it basically starts by singling decisions and following them down a path. I’m going to pull up a classic example from http://jmvidal.cse.sc.edu/talks/decisiontrees/allslides.html:

Suppose we want to go play tennis. We look at the sky to see whether it is sunny, overcast, or raining. If it’s overcast, we play tennis. If it’s raining, we look at the wind. If the wind is strong, we won’t play, and if it’s weak, we’ll play. If it’s sunny, we’ll look at the humidity, where we play if the humidity is normal and we won’t play if it’s high.
You’ll see that we make single decisions based on one variable, and work down our tree to come to a conclusion that we hope is correct. There are a lot of algorithms on how to build such decision trees, but we’re not going to go over them here.
At any rate, now that we’ve chosen to switch our classifier to J48, we see our tree:

We can now see exactly how decisions are made based on the tree, where if num_link > 3 we say True. If it’s less than 3, we’ll take a look at whether the email contains the word html, which splits the tree into two branches. Then we keep going down things such as num_link and numwords until we have a decision.
As you can also see from the screenshot above, our correctly classified instances has improved to 76.6%
How to decide which rule is more important than the other
I’m going to give a simplified answer because the real answer is going to be very complicated and long. Basically, there is a notion of something called “information”, or knowledge. We can ask ourselves, “how much information do I gain by looking at this feature?”
For example, if we have two features: sunny and windy. We play tennis on 4 sunny days and 4 cloudy days, and don’t play tennis on 2 sunny days and 2 cloudy days. This information doesn’t really help us – we don’t gain anything by looking at whether it’s sunny or not, as it’s sort of even both ways.
If we look at windy days, and every time it’s windy we don’t play tennis, and if it’s windy we always play tennis, then we sort of gain a lot of information by examining the windy feature. Therefore, looking at how windy a day is will be much more beneficial than looking at how sunny it is because we don’t gain anything by looking at how sunny it is.
Looking at our model, you’d notice that we look at the number of links first, which means the number of links is the feature with the most information. We can actually look at raw numbers for information gain through Weka.
Let’s go to the Select attributes tab, choose InfoGainAttributeEval , and click start. We’d get this:
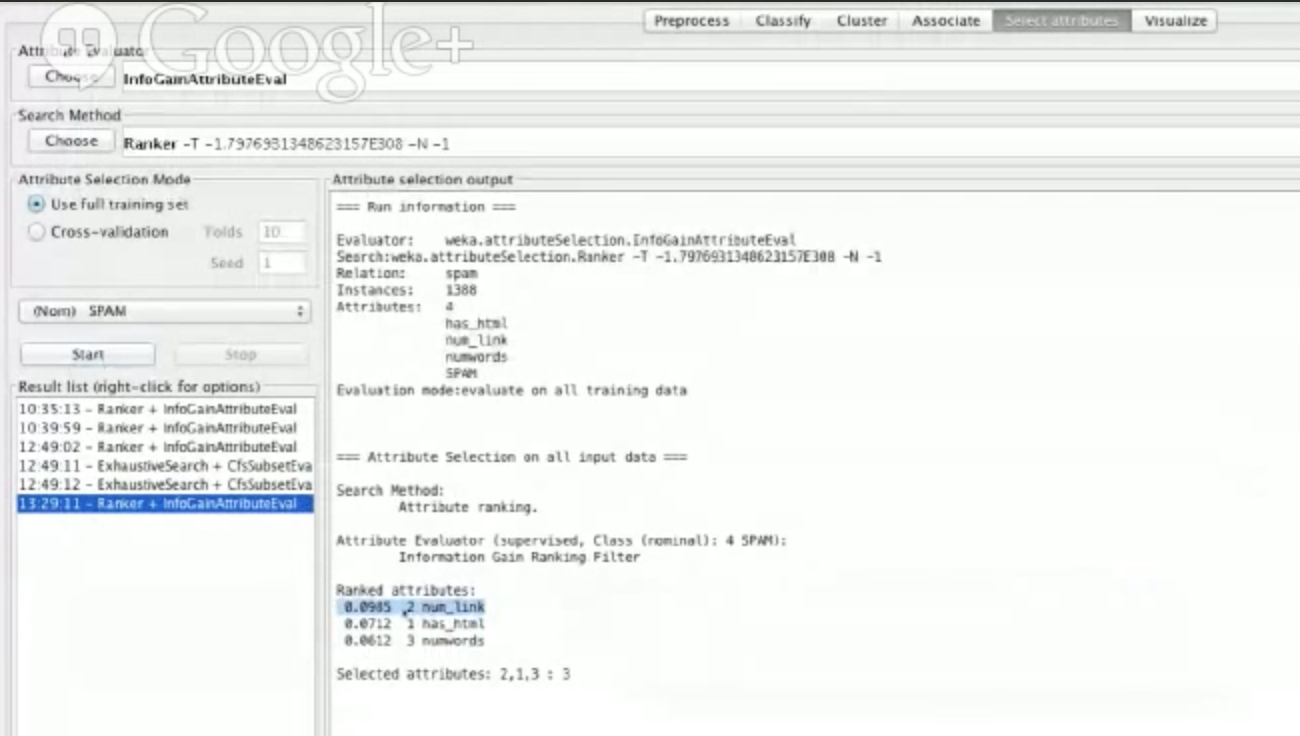
We don’t have to care what all the numbers mean, but we can see that num_link has the most information gained, followed by has_html and then numwords. In other words, num_link is our best feature.
To illustrate this further, we can add a dummy feature to our features.py:
def dummy(emailtext):
return 1
This feature will return 1 regardless of what kind of email it is. If we run feature_extract.py and reload our spam.arff into Weka, we should see that there was no information gain from looking at our dummy feature:
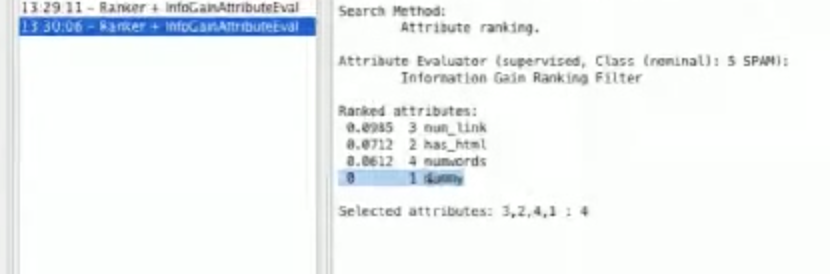
This is because it’s the same for everything.
To sum it all up, we basically look at the features that give us the most knowledge gain.
Over-fitting
Now we want to have more features to help us tell spam apart from emails that are not spam. Again, these will be ways to transform the entire text from an email from something we understand to something a computer understands, which is a single numerical or binary feature.
One of the Codementor users in the office hour suggested specific words that are historically spammy as a feature, such as “free”, “buy”, “join”, “start”, “click”, “discount”. Let’s add this feature to our features.py and break the text up with spaces so we’ll get all our words.
def spammy_words(emailtext):
spam_words = ['join', 'free', 'buy', 'start', 'click', 'discount']
splittext = emailtext.split(" ")
total = 0
for word in spam_words:
total += splittext.count(word) #appends the count of each of these words to total
return total
Let’s give this feature a shot and re-load our spam.arff in Weka.

We can see a distribution where most of our emails that are not-spam contain zero words from the spam_words array, and as the count increases the bars get bluer where it means if there are more spam_words the email contains the more likely it is going to be spam.
Let’s also take a look at the information gain:
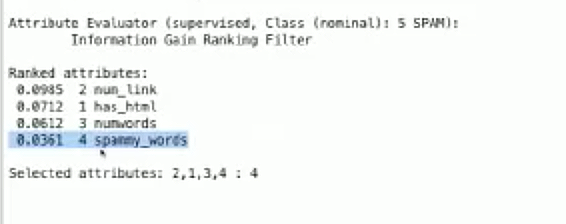
We can see there is some information gain, but not a whole lot.
As far as our classifier goes, we can see we actually had a slight drop in accuracy:

Not to say spammy_words is a bad feature as it’s a pretty good one in my opinion, let’s ask ourselves what would be the possible reason our classification accuracy dropped.
Personally, I think the accuracy dropped because of over-fitting. If you look at the tree in our Weka, you’ll see that we’ve generate a lot of rules – I estimate at least 50 rules, and many of them are really specific.

We may be looking too specifically at the data we have, and making rules that are too specific for our testing data, especailly as our spammy_words feature didn’t contribute a lot of information gain. While we can experiment with classifiers and tweak our parameters to see whether we can increase our classifier accuracy, but let’s just try to fix our spammy_words feature.
Previously, we thought of words that, to us, indicates spam. However, as humans we are biased based on our experience, but the words we thought of might not be present in our dataset. Or, it could mean that using the word ‘free’ for example is just as regular in common email, just less prevalent.
We want to figure a way to filter for spammy_words but automatically generate the list of words instead of having to figure it out ourselves.
To do this we should take a look at the distribution of words. First we should set dictionaries for spamwords and notspamwords, and we’re going to fill those up as follows:
import os, glob
spamwords = {}
notspamwords = {}
spam_directory = "is-spam"
not_spam = "not-spam"
os.chdir(spam_directory)
for email in glob.glob("*"):#ITERATE THROUGH ALL DATA HERE
text = open(email).read().lower().split(‘ ') #gets all the text of our emails and normalizes them to lower case
for word in text:
if word in spamwords:
spamwords[word] += 1
else:
spamwords[word] = 1
print spamwords
Let’s save the code above as a file named wordcounts.py and run it. We’ll see that it’s a big mess containing a huge dictionary of all our words and how often we saw them. It’s got links and html, but we’re going to ignore that and basically print out the words we see most by changing print spamwords to
keys = sorted(spamwords.keys(), key=lambda x: spamwords[x], reversed=True`)
for word in keys:
print word, spamwords[word]
Where we will sort the keys and order them by how often they are seen.
And we’ll see that our most seen words are very common (e.g. for, a, and, you, of, to, the). At first this seems kind of bad, as these don’t help us. We can’t look for the word “a” because it’s going to be all over in both spam and non-spam emails.
So, to really figure out what words are commonly used in spam emails but not commonly used in not-spam emails, let’s take a look at commonly used words in not spam emails with the same code except we change os.chdir(spam_directory) to os.chdir('../'+not_spam).
We’ll notice that, strangely, Helvetica is a word commonly found in spam emails but not in not-spam emails. New, money, e-mail, receive, and business are also found in spam emails but less-so in not-spam email, so let’s make changes to our spammy_words feature:
def spammy_words(emailtext):
spam_words = ['helvetica', 'new', 'money', 'e-mail', 'receive', 'business']
splittext = emailtext.split(" ")
total = 0
for word in spam_words:
total += splittext.count(word) #appends the count of each of these words to total
return total
Let’s also make a feature for not spammy words, which might be just as helpful. Interestingly, email is spelled differently.
def not_spammy_words(emailtext):
spam_words = ['email', 'people', 'time', 'please']
splittext = emailtext.split(" ")
total = 0
for word in spam_words:
total += splittext.count(word) #appends the count of each of these words to total
return total
After adding these two features, we should see in our Weka that we’re now close to 79% accuracy. There’s actually a lot of interesting things we can look at just by examining the actual words we see. We can train our machine for words or even combinations of words in bigrams (pairs of words) or trigrams (three groups of words). For example, maybe “free” is a word found in both spam and not-spam email, but “free money” is only found in spam emails. We can make features that say “free money” is spam but “free” and “money” are not spam.
Additional Features
One thing you may have noticed by looking through the dataset or through experience is that spammers tend to “shout” in their emails and use a lot of all caps, while normal people seldom do that. Let’s try to add two features based on this observation. One is if the emails is in all caps, the other is the ratio of all capital letters to lower case as it’s unlikely for an email to be in all caps.
def all_caps(emailtext):
return 1 if emailtext == emailtext.upper() else 0
def cap_ratio(emailtext):
lowers = float(len([f for f in emailtext if f == f.lower()]))
uppers = float(len([f for f in emailtext if f == f.upper()]))
return uppers/lowers

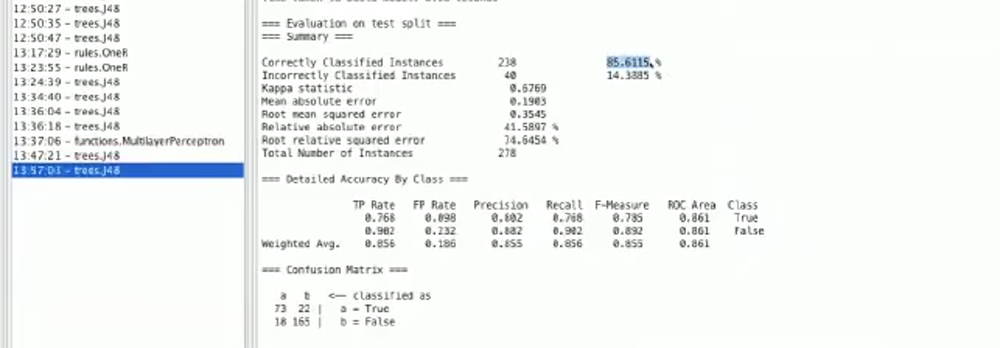
Looking at our Weka, we can see that all_caps doesn’t give us much information, but cap_ratio’s data seems to tell us a lot, and if we look at the graph distribution it seems like anything with a ratio above the mean is almost always spam.

Just adding the cap_ratio feature made our accuracy jump to almost 86%.
Final Words
As we add more features, our model will become slower to train because it takes time to learn these patterns. By the time we’ve finished this exercise we have 7 features, which isn’t so bad.
Weka has a great function in Select attributes where it will suggest you which features to train on:
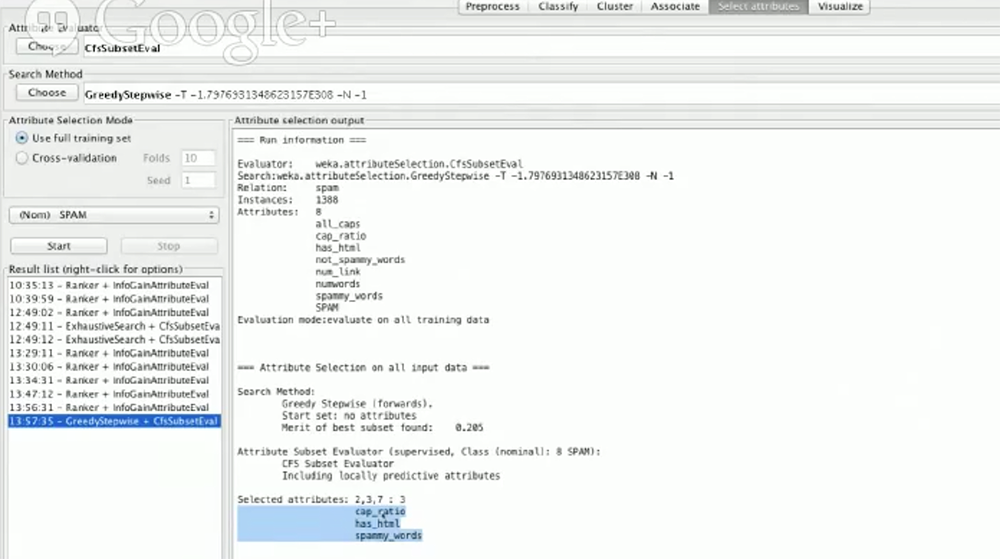
As you can see, it recommends us to use cap_ratio, has_html, and spammy_words. So if we deselect the other features in our preprocess tab and then check the accuracy in our classifier, we’d probably get something similar to 86% despite only telling our machine to look at 3 features.
I encourage you guys to go and implement your own features based on what you learned and see if you can improve the classifier results. I hope this activity was informative for you to get started with machine learning & NLP.
How would I construct a function that reads data from a file containing the spam email messages
Hello
The feture_extract.py file has the following UnicodeDecodeError: ‘charmap’ codec can’t decode byte 0x81 in position 615: character maps to <undefined>
Reloaded modules: features
Traceback (most recent call last):
File “E:\Cursos\Python\Pro_weka\feature_extract.py”, line 63, in <module>
main()
File “E:\Cursos\Python\Pro_weka\feature_extract.py”, line 33, in main
extract_features(open(email).read(), feature_funcitons, arff, True)
File “C:\Users\rober\anaconda3\lib\encodings\cp1252.py”, line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
encoding=‘utf-8’, errors=‘ignore’